




ทีมวิจัยจาก Allen Institute for Artificial Intelligence ประกาศว่าได้คิดค้น FlexOlmo แนวทางใหม่ในการพัฒนาโมเดลภาษา ที่สามารถเพิ่มความเป็นส่วนตัวของข้อมูลสำหรับฝึกอบรมได้
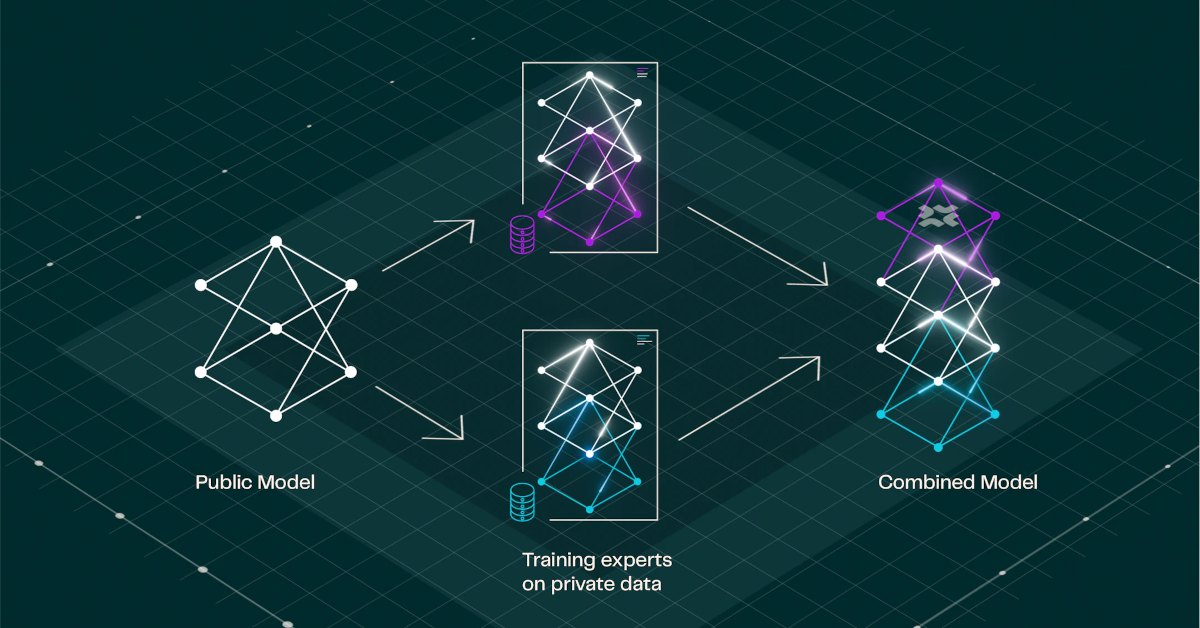
ยิ่งชุดข้อมูลที่ใช้ฝึกเครือข่ายประสาทเทียมมีคุณภาพดีมากเท่าไร ผลลัพธ์ที่ได้จากโมเดลก็ยิ่งดีขึ้นเท่านั้น หนึ่งในวิธีการเพิ่มคุณภาพของชุดข้อมูลฝึกคือการรวมข้อมูลจากหลายองค์กรเข้าด้วยกัน เช่น สถาบันวิจัยทางการแพทย์สองแห่งอาจรวมข้อมูลเวชระเบียนไว้ในคลังข้อมูลเดียวกัน และใช้ข้อมูลนั้นในการฝึก AI ร่วมกัน
ในทางปฏิบัติ การแบ่งปันข้อมูลลักษณะนี้ไม่สามารถทำได้เสมอไป ข้อจำกัดด้านกฎระเบียบและความท้าทายด้าน ความมั่นคงปลอดภัย มักทำให้ไม่สามารถเคลื่อนย้ายข้อมูลการฝึกออกนอกเครือข่ายขององค์กรได้ FlexOlmo ถูกออกแบบมาเพื่อแก้ไขข้อจำกัดนี้
ตามคำอธิบายของผู้พัฒนา เทคโนโลยีนี้ทำให้หลายบริษัทสามารถฝึกโมเดล AI ร่วมกันได้โดยไม่ต้องเปิดเผยชุดข้อมูลให้แก่กัน ซึ่ง FlexOlmo “สามารถสร้างประสิทธิภาพได้ใกล้เคียงมาก” กับโมเดล AI ที่ฝึกด้วยชุดข้อมูลแบบรวม นักวิจัยระบุในบล็อกโพสต์
จุดเริ่มต้นของโครงการ FlexOlmo คือโมเดล AI ที่เรียกว่า Anchor โดยแต่ละองค์กรที่เข้าร่วมจะสร้างสำเนาของ โมเดล Anchor ขึ้นมา แล้วทำการฝึกโมเดลนั้นด้วยข้อมูลภายในของตนเอง จากนั้นโมเดลที่ปรับแต่งแล้วจากแต่ละองค์กรจะถูกรวมเข้าด้วยกันเป็นอัลกอริทึมเดียว
“การออกแบบนี้ทำให้เจ้าของข้อมูลสามารถมีส่วนร่วมได้แบบอะซิงโครนัส โดยไม่ต้องแชร์ข้อมูลของตน” นักวิจัยอธิบายในบทความ
โมเดล AI ที่ประกอบด้วยเครือข่ายประสาทเทียมหลายตัวเรียกว่า MoE หรือ Mixture of Experts โมเดลแบบนี้จะมีส่วนประกอบที่เรียกว่าเราเตอร์ ซึ่งทำหน้าที่เลือกเครือข่ายประสาทเทียมที่เหมาะสมที่สุดในการตอบคำถามที่ผู้ใช้ป้อนเข้ามา
การฝึกเครือข่ายประสาทเทียมของโมเดล MoE ด้วยชุดข้อมูลที่แตกต่างกัน ซึ่งเป็นแนวทางของ FlexOlmo อาจทำให้ประสิทธิภาพของเราเตอร์ลดลง เพื่อแก้ปัญหานี้ เทคโนโลยีดังกล่าวจึงกำหนดให้เครือข่ายประสาทเทียมแต่ละตัวมีเราเตอร์ของตัวเอง เมื่อรวมอัลกอริทึมทั้งหมดเป็นโมเดล MoE เดียวกัน เราเตอร์แต่ละตัวก็จะถูกรวมเข้าด้วยกันด้วย วิธีนี้ช่วยหลีกเลี่ยงปัญหาทางเทคนิคที่อาจเกิดขึ้นได้
นักวิจัยได้ทดสอบว่าแฮ็กเกอร์สามารถดึงข้อมูลการฝึกจากเครือข่ายประสาทเทียมแต่ละตัวในโมเดล FlexOlmo ได้หรือไม่ “การวิเคราะห์ของเราพบว่าอัตราการดึงข้อมูลมีเพียง 0.7%” พวกเขาระบุ “เพื่อเปรียบเทียบ โมเดลที่ overfit กับชุดข้อมูลคณิตศาสตร์ขนาดเล็ก 100 รอบ มีอัตราการดึงข้อมูลถึง 60%”
เพื่อประเมินการใช้งาน FlexOlmo ในทางปฏิบัติ นักวิจัยได้นำไปใช้ในการฝึกโมเดล AI หลายตัวที่มีจำนวนพารามิเตอร์สูงถึง 37 พันล้านตัว ผลการทดสอบพบว่า เทคโนโลยีนี้สามารถเพิ่มประสิทธิภาพของโมเดลได้ดีกว่าแนวทางการรวมเครือข่ายประสาทเทียมแบบเดิมถึง 10.1%
ที่มา: https://siliconangle.com/2025/07/10/new-flexolmo-language-model-design-removes-need-training-data-sharing/











