




จากงาน Meta Connect วันนี้ ทาง Meta ได้ปล่อยโมเดล Llama 3.2 ออกมาอย่างเป็นทางการ โดยถือว่าเป็น โมเดล Multimodal ที่เป็น Open Source ตัวแรกของบริษัทที่สามารถเข้าใจได้ทั้งภาพและข้อความที่มีความสามารถเทียบเคียงกับโมเดลของ Anthropic และ OpenAI แล้วด้วย

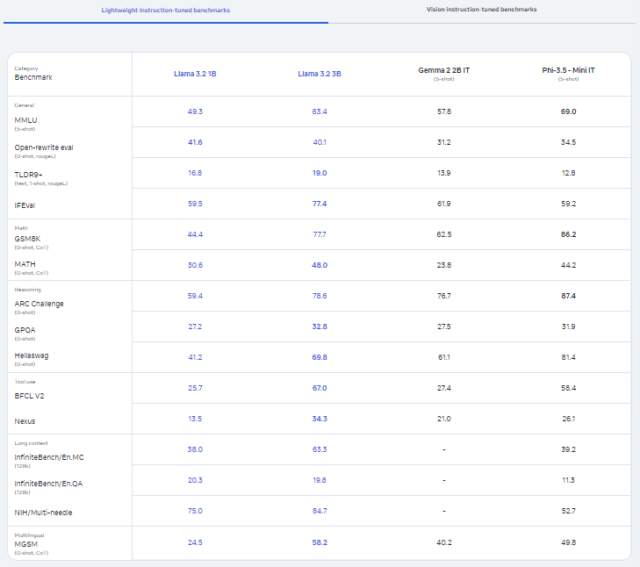
สำหรับ Llama 3.2 ที่ปล่อยออกมาครั้งนี้จะมีหลากหลายขนาด คือขนาดเล็ก (11B พารามิเตอร์) และขนาดกลาง (90B พารามิเตอร์) และขนาดเบา (Lightweight) ที่รองรับเฉพาะข้อความเท่านั้น (1B และ 3B พารามิเตอร์) ที่สามารถเข้ากับอุปกรณ์โทรศัพท์มือถือหรือว่า Edge ต่าง ๆ ได้ด้วย
โดย Llama 3.2 นั้นจะมี Context Window ยาว 128.000 Token เท่ากับตัวก่อนหน้า ซึ่งนั่นหมายความว่าผู้ใช้งานจะสามารถใส่ Input ข้อความได้มากเทียบเท่ากับหน้าหนังสือหลักร้อยหน้าเช่นกัน
Llama 3.2 ขนาดเล็กและกลางนี้สามารถสนับสนุนการจัดการภาพได้ในหลากหลาย Use Case รวมทั้งยังสามารถเข้าใจแผนภาพ (Chart) หรือว่ากราฟ (Graph) ต่าง ๆ ภาพคำบรรยาย หรือว่าการระบุไปยังวัตถุจากรายละเอียดที่เป็นภาษธรรมชาติได้ด้วย
ที่น่าสนใจ Meta เผยว่า Llama 3.2 นี้สามารถแข่งขันกับ Claude 3 Haiku ของ Anthropic และ GPT4o-mini ของ OpenAI ในการรู้จำภาพและงานความเข้าใจในภาพต่าง ๆ ได้แล้ว
“นี่คือ Open-Source Multimodal Model ตัวแรกของพวกเรา มันจะทำให้เกิดแอปพลิเคชันอีกมากมาย ที่จะต้องใช้ความเข้าใจในด้านภาพ” CEO แห่ง Mark Zuckerburg กล่าว
ครั้งนี้ถือเป็นครั้งแรกที่มีการปล่อยโมเดล Llama ออกมาในหลากหลายรุ่น ที่จะทำให้นักพัฒนาระบบสามารถทำงานร่วมกับโมเดลได้ในหลากหลายทรัพยากร เช่น บน On-Premises หรือว่ารันบนอุปกรณ์มือถือ พีซี หรือว่าบน Node ตัวเอง ซึ่งจะสามารถใช้งานได้อย่างยืดหยุ่นมากขึ้น
และด้วยโมเดล Open Source ที่มีประสิทธิภาพมากขึ้นเรื่อย ๆ และสามารถใช้งานได้ในหลากหลายอุปกรณ์มากยิ่งขึ้น คำกล่าวที่ว่า “AI is the new electricity” คงไม่ไกลเกินจริงแน่นอน
สำหรับใครที่สนใจอยากดาวน์โหลด Llama 3.2 ไปใช้งานสามารถดาวน์โหลดได้ที่ Hugging Face
ที่มา: https://venturebeat.com/ai/meta-llama-3-2-vision-models-to-rival-anthropic-openai/










