




Microsoft ได้เปิดโปรเจ็คที่ใช้ภายในองค์กรและริเริ่มขึ้นตั้งแต่ปี 2017 ที่ชื่อ Data Accelerator เป็นโอเพ่นซอร์สซึ่งได้โฆษณาว่าจะช่วยให้การทำ Data Pipeline กับข้อมูล Big Data เป็นเรื่องง่ายขึ้น
Data Accelerator (for Apache Spark) ถูกใช้เพื่อการ Streaming Big Data ซึ่งช่วยให้การสร้าง แก้ไข และจัดการงานของ Spark บน AzureHDInsights เป็นเรื่องง่ายและมีประสิทธิภาพซึ่งอันที่จริงแล้วทาง Microsoft เริ่มใช้เป็นการภายในมาระยะหนึ่งแล้วกับการประมวลผลข้อมูลที่เข้ามาจากหลายผลิตภัณฑ์ของตนที่มีปริมาณมหาศาล
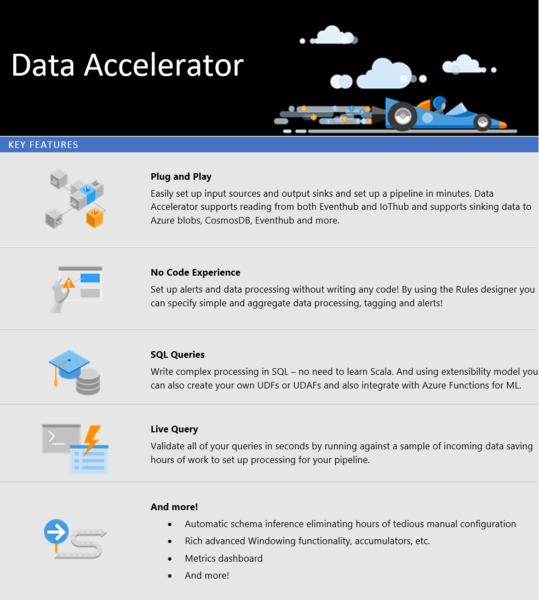
สำหรับข้อดีที่ Data Accelerator นำเสนอมีดังนี้
- การตั้งค่า Alert และ Rule ทำได้โดยไม่ต้องเขียนโค้ด
- สามารถเขียน Spark SQL query ได้อย่างฉับไวด้วยส่วนเพิ่มเติม เช่น LiveQuery, time windowing, in-memory accumulator เป็นต้น
- สามารถทำงานร่วมกับโค้ดปรับแต่งผ่าน Scala หรือ Azure Function ก็ได้
ที่มา : https://azure.microsoft.com/en-us/blog/microsoft-open-sources-data-accelerator-an-easy-to-configure-pipeline-for-streaming-at-scale/ และ https://cloudblogs.microsoft.com/opensource/2019/04/16/microsoft-open-sources-data-accelerator-for-apache-spark/



