หากคุณกำลังเป็นคนหนึ่งที่สงสัยถึงคำศัพท์ที่ปรากฏตัวขึ้นใหม่อย่าง ‘Observability’ ในบทความนี้เราขอพาทุกท่านไปรู้จักกับคำ ๆ นี้ให้มากขึ้น และแนวคิดที่ทำให้เครื่องมือด้าน Observability แตกต่างกับเครื่องมือด้าน Monitoring อยู่หลายประการ
นอกจากนี้เราจะพาทุกท่านไปรู้จักกับผู้นำตลาดด้าน APM & Observability ที่การ์ทเนอร์ยกย่องให้เป็นอันดับหนึ่งในปี 2023 พร้อมทั้งความคลุมเครือใหม่ระหว่าง APM และ Observability ถ้าพร้อมกันแล้ว ขอเชิญทุกท่านเข้ามาติดตามกันเลยครับ

Observability vs Monitoring
ก่อนที่เราจะเข้าใจความต่างของคำศัพท์ทั้งสองนี้ เป็นเรื่องจำเป็นที่ต้องเรียนรู้เกี่ยวกับนิยาม และความคล้ายคลึงที่ทั้งสองแนวคิดมีร่วมกันเสียก่อน โดยคำว่า Observability เป็นความสามารถที่จะเข้าใจสถานะของระบบภายในโดยการวิเคราะห์ข้อมูลที่ถูกสร้างออกมาประกอบด้วย Log, Metric และ Traces ซึ่งเมื่อเข้าใจว่าเกิดอะไรขึ้น จึงนำไปสู่ความสามารถที่จะตรวจสอบและแก้ไขสาเหตุแห่งปัญหา
ในนิยามของ Monitoring กล่าวถึงกระบวนการที่รวบรวม วิเคราะห์ และใช้ข้อมูลเพื่อติดตามการดำเนินงานของโปรแกรมให้ดำเนินไปตามวัตถุประสงค์พร้อมทั้งแนะนำในการตัดสินใจได้ โดยจะเน้นไปที่การจับตา Metric ที่สนใจ และอาจได้ข้อมูลเพิ่มจาก Log เข้ามา
อย่างไรก็ดี ทั้งสองแนวทางต่างมุ่งเป้าไปที่เป้าหมายเดียวกันคือ การให้ข้อมูล Insight ที่บ่งชี้ไปถึงสุขภาพ ประสิทธิภาพ และพฤติกรรมของระบบด้วยการประมวลข้อมูลที่เก็บมาวิเคราะห์และแสดงผล เพื่อสุดท้ายแล้วจะนำไปสู่การตรวจสอบและแก้ไขปัญหา เพียงแต่ทั้งสองจะมีวิธีการในแบบของตัวเอง ในหลายกรณีองค์กรอาจต้องใช้สองโซลูชันควบคู่กันแล้วแต่วัตถุประสงค์
ความแตกต่างที่ทำให้เกิดการใช้งานที่ต่างกันออกไปก็คือ Monitoring มักจะสนใจเจาะจงไปยัง Metric บางอย่าง ซึ่งเหมาะกับระบบที่มีความรู้เข้าใจกันดี เช่น เราทราบว่าระบบจะล่มเมื่ออัตราการอ่านเขียนฐานข้อมูลสูงเกินไปที่แอดมินประสบการณ์สูงจะทราบได้ว่าปัญหาเริ่มเกิดขึ้นเมื่อค่า Memory และ CPU ขึ้นสูง ดังนั้น ค่า Metric ที่สนใจอย่าง Utilize Rate ก็อาจถูกนำไปใช้ติดตามปัญหาผ่านแดชบอร์ดที่ช่วยให้ทราบปัญหาได้
อีกมุมหนึ่ง แอปพลิเคชันสมัยใหม่กลับเผชิญกับความซับซ้อนมากขึ้น ทำให้โอกาสที่จะทราบปัญหาอย่างแน่ชัดเป็นไปได้ยาก หากวิเคราะห์จากปัจจัยของ Cloud, Microservice และ Container เป็นต้น สิ่งเหล่านี้ได้เพิ่มความท้าทายให้กับการติดตามสถานการณ์ของระบบอย่างที่ไม่เคยมีมาก่อน ดังนั้น การเชื่อมโยง Metric ไม่กี่ตัวเข้าด้วยกันจึงไม่ตอบโจทย์ นั่นจึงเป็นที่มาของ Observability ที่ทำการวิเคราะห์ Input/Output เพื่อเรียนรู้เกี่ยวกับการทำงานภายในระบบ นำไปสู่การแก้ปัญหาได้อย่างรวดเร็ว
ความท้าทายของ Observability

Observability มีแรงผลักดันจากโครงสร้างสถาปัตยกรรมอย่าง Cloud Native ด้วยการที่ระบบกระจายตัวออกไป ไอเดียหลักของการจัดการปัญหาก็คือ ความสามารถในการรับข้อมูลที่เกิดขึ้นมาจากทุกองค์ประกอบของระบบ เช่น Hardware, Software, Endpoint, Service, Cloud Infrastructure และอื่น ๆ ซึ่งความท้าทายก็คือ
- Data-Silo : แหล่งที่มาที่แยกกันมักทำให้วิธีการรวมข้อมูลเหล่านี้ไม่ง่าย เพราะอาจต้องใช้ Agent มากกว่า 1 ตัว ประกอบกัน สร้างความยุ่งยากขึ้นมา
- Data Attribute : ปริมาณของข้อมูลที่หลั่งไหลมาจากทุกทิศทุกทางมีมหาศาล ดังนั้น โซลูชันต้องวางแผนเรื่องการจัดเก็บ และการจัดการข้อมูลดิบที่อาจเป็น Structured หรือ Unstructured
- Manual Config : หลายครั้งที่ผู้ปฏิบัติงานด้านไอทีต้องตั้งค่าเครื่องมือด้าน Observability ของตนใหม่ เมื่อเผชิญกับส่วนประกอบใหม่ที่ถูกเพิ่มขึ้นมาในระบบ ดังนั้น ระบบที่ดีควรมีความยืดหยุ่นต่อการเพิ่มของปัจจัยใหม่
- Troubleshooting : จะทำอย่างไรให้ทุกทีมมีภาพในทิศทางเดียวกัน ที่ฉายภาพให้เข้าใจได้ในมุมมองของตนตามทักษะที่ถนัด
ทั้งนี้ การที่จะกล่าวว่าระบบของท่านสามารถถูกเฝ้าดู (Observable) ได้นั้นมีข้อมูลอยู่ 3 มุมมองที่ต้องรู้จักคือ
1. Logs
ข้อมูลที่อาจมีโครงสร้าง (Structured) หรือไร้โครงสร้าง (Unstructured) ซึ่งเนื้อหาจะอธิบายถึงข้อมูลเกี่ยวกับแอปพลิเคชันและระบบที่มีรายละเอียดว่า ปฏิบัติการและการเดินทางเป็นอย่างไร เช่น Log ที่อธิบายถึงอีเวนต์ก็จะเริ่มตั้งแต่ว่าโปรเซสได้เป็นผู้เริ่มงาน การจัดการข้อผิดพลาด และอื่น ๆ โดย Logs จะให้ข้อมูลเติมเต็ม Metric ถึงสถานะของแอปพลิเคชัน เช่น เปอร์เซ็นต์ความผิดพลาดจากฟังก์ชัน API
2. Metric
เป็นการกำหนดมาตรวัดที่เกิดขึ้นในระยะเวลาหนึ่ง เช่น มาตรวัดอัตราการใช้ CPU ความเปลี่ยนแปลงของ Throughput หรือจำนวนของความผิดพลาดที่เกิดขึ้นจากฟังก์ชัน API ในรอบชั่วโมงที่ผ่านมา โดย Metric อาจถูกใช้เพื่อให้สัญญาณแรกของปัญหา แต่ Logs จะมีรายละเอียดว่าอะไรน่าจะเป็นปัจจัยเกี่ยวข้องกับปัญหา หรืออะไรได้รับผลกระทบ
3. Tracing
เป็นกิจกรรมที่เกิดขึ้นของ Transaction หรือ Request หนึ่ง ซึ่งจะช่วยติดตามว่าแอปพลิเคชันและบริการต่าง ๆ นั้นติดต่อกันอย่างไรบ้าง เจาะลึกได้ไปถึงระดับโค้ดว่ามีรายละเอียดอย่างไร
ประโยชน์ของ Observability
วัตถุประสงค์ของโซลูชันด้าน Observability คือ การช่วยให้องค์กรเข้าถึงต้นตอปัญหาได้อย่างตรงประเด็นว่าเกิดอะไรขึ้นและควรทำอย่างไรต่อไป ซึ่งความรวดเร็วตรงนี้ยังส่งผลดีต่อการป้องกันปัญหาในเชิงรุก นั่นก็คือการรับทราบเพื่อแก้ไขได้ก่อนที่ผู้ใช้งานจะรู้ตัว ตอบโจทย์ระบบดิจิทัลสมัยใหม่ขององค์กรที่หลากหลายจนนำไปสู่ความซับซ้อนและปัญหาใหม่ ๆ อย่างไรก็ดี ในแง่ของประโยชน์ที่เกิดขึ้น มีหลายตัวอย่างที่เห็นภาพได้ชัดเจนจากการมีโซลูชันด้าน Observability ดังนี้
1. Application Performance Monitoring (APM) – ช่วยให้องค์กรมองเห็นประสิทธิภาพของแอปพลิเคชันแบบ Cloud Native ที่ใช้แนวคิด Microservice หรือ Container ได้อย่างรวดเร็ว พร้อมทั้งต่อยอดทำการปฏิบัติการแบบอัตโนมัติ ส่งเสริมการทำงานของทีมแอปพลิเคชันและ Operation
2. DevSecOps/Site Reliable Engineer(SRE) – ส่งเสริมทีมพัฒนาและดูแลแอปพลิเคชันให้มีความพร้อมในการใช้งาน อย่างไรก็ดี ไม่เพียงอาศัยเครื่องมือเพียงด้านเดียว เพราะแนวทางปฏิบัติที่ดีคือ การที่นักพัฒนาจะต้องใส่ใจตั้งแต่การออกแบบให้ระบบถูกเฝ้าดูได้ด้วย เพื่อในวันข้างหน้าทีมดูแลแอปและนักพัฒนาเองจะได้ข้อมูลเหล่านี้ช่วยในการปรับปรุงประสิทธิภาพแอป ปลอดภัยและทนทานมากขึ้น
3. End-user Experience – ผู้ใช้งานจริงคือปราการด่านสุดท้ายที่กระทบกระเทือนต่อรายรับขององค์กร ซึ่งประสบการณ์ที่เกิดขึ้น ณ ปลายทางเหล่านั้น อาจส่งผลต่อรายรับขององค์กรและภาพลักษณ์ขององค์กรได้อย่างมีนัยสำคัญ ดังนั้น แนวทางที่ดีที่สุดคือ องค์กรต้องรับรู้และแก้ไขต้นเหตุได้ก่อนที่ผู้ใช้งานจะทราบ นอกจากนี้ โซลูชันควรมีการจำลองปัญหาที่เกิดขึ้นได้จากข้อมูลที่มี เพื่อนำมาปรับปรุงให้การทำงานดีขึ้นและเห็นปัญหาได้ในมุมของผู้ใช้
4. Business Analytics – องค์กรสามารถผสมผสานข้อมูลการวิเคราะห์แอปพลิเคชัน เพื่อเชื่องโยงไปยังผลกระทบและการตัดสินใจต่อธุรกิจได้ เช่น SLA ที่เกิดขึ้นสอดคล้องกับวัตถุประสงค์ของธุรกิจหรือไม่ เป็นต้น
APM & Observability ในมุมของการ์ทเนอร์
APM และ Observability ยังมีความคลุมเครือในเรื่องของความชัดเจนอยู่ไม่น้อย แม้แต่การ์ทเนอร์เองที่เป็นสถาบันจัดอันดับเทคโนโลยีระดับโลกยังจัดกลุ่มตลาดของ 2 ศัพท์นี้ไว้ในหมวดเดียวกัน โดยเพิ่มคำว่า Observability เข้ามาในปี 2022 โดยการ์ทเนอร์ได้ชี้แจงในเอกสารช่วงท้ายว่า Monitoring ส่วนใหญ่มักถูกสร้างขึ้นให้ตอบโจทย์การทำงานที่แยกขาดกันภายในองค์กร เช่น APM, NPM, ITIM และอื่น ๆ ซึ่งดูเหมือนว่าจะมีความเฉพาะเจาะจงมากกว่า Observability แต่หากถามความเห็นจาก Vendor ที่เข้าร่วมชิงชัยในการจัดอันดับบ้างก็มองว่า APM เป็นส่วนหนึ่งของ Observability และส่วนใหญ่มักชี้ว่าตนให้บริการได้ทั้ง APM และ Observability
นิยามของตลาด APM และ Observability ที่การ์ทเนอร์แนะนำไว้ก็คือ ซอฟต์แวร์ที่ช่วยให้ผู้ใช้สังเกตและวิเคราะห์ สุขภาพ ประสิทธิภาพ และประสบการณ์ของผู้ใช้งาน โดยมักถูกใช้งาน IT Operation, Site Reliable Engineer, Application Developer, ทีม Cloud และแพลตฟอร์ม ตลอดจนเจ้าของผลิตภัณฑ์ ทั้งนี้อาจนำเสนอได้ในรูปแบบของ SaaS และการจัดการจากผู้ใช้ หรือจัดการโดย Vendor แต่คุณสมบัติสำคัญที่ควรจะมี คือ
- สามารถเฝ้ามองสังเกตพฤติกรรมการทำงานของแอปพลิเคชันได้ตลอด Transaction
- ค้นหาและจับคู่แอปพลิเคชันกับส่วนประกอบใน infrastructure ได้อย่างอัตโนมัติ
- มอนิเตอร์แอปพลิเคชันที่ทำงานผ่าน เบราว์เซอร์ มือถือ และ API ได้
- ระบุและวิเคราะห์ปัญหาด้านประสิทธิภาพของแอปพลิเคชัน และผลกระทบต่อธุรกิจ
- ทำงานเข้ากันได้กับเครื่องมืออัตโนมัติ บริการการจัดการต่าง ๆ หรือ Public Cloud เช่น Amazon Cloudwatch, Azure Monitoring และ Google Cloud Operation เป็นต้น
- มอนิเตอร์กิจกรรมทางธุรกิจและวิเคราะห์ KPI จากการเข้าใจงานของผู้ใช้
- วิเคราะห์ข้อมูล Telemetry ได้หลากชนิดทั้ง Logs, Metric และ Trace โดยสามารถค้นหาและอธิบายสาเหตุของเหตุการณ์หรือความผิดปกติได้
- มีฟังก์ชันด้านความมั่นคงปลอดภัยของแอปพลิเคชัน เช่น ทราบถึง Known Vulnerability และติดตามการใช้งานที่ได้รับผลกระทบจากช่องโหว่เหล่านั้น
นอกจากนี้ยังมีมุมของฟังก์ชันเสริมที่อาจจะมีได้ เช่น
- การติดตามไปถึงระดับ Endpoint และเข้าใจประสบการณ์ของผู้ใช้งาน
- รับข้อมูล Telemetry จากแอปพลิเคชันที่โฮสต์หรือ SaaS ได้
- ทำงานเข้ากันได้กับเครื่องมือของทีม DevOps เพื่อเร่งกระบวนการทำงานได้ไวมากขึ้น
- มีเครื่องมือทดสอบประสิทธิภาพและทำงานร่วมกับเครื่องมือทดสอบโหลด
- ค้นหาพร้อมแนะนำวิธีการแก้ไขปัญหาสุขภาพและประสิทธิภาพโดยใช้การวิเคราะห์ขั้นสูง (อาจกล่าวได้ว่าเป็นฟีเจอร์ AIOps)
Dynatrace ผู้นำตลาดด้าน APM & Observability ในปี 2023
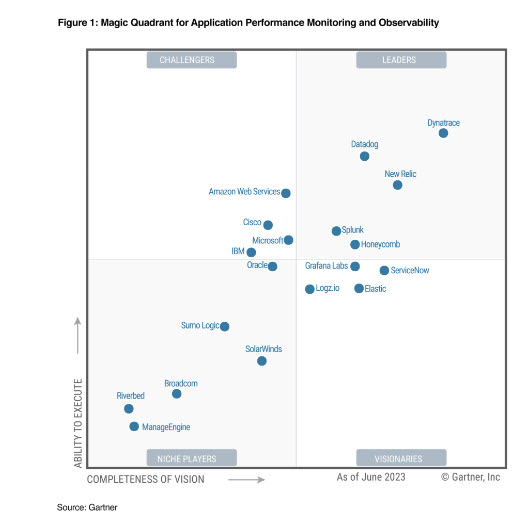
หลายปีที่ผ่านมา Dynatrace ได้ถูกจัดอันดับอยู่ในสภาวะผู้นำของตลาดด้าน APM และ Observability โดยเฉพาะในปี 2023 ความยอดเยี่ยมของโซลูชันจาก Dynatrace ที่การ์ทเนอร์กล่าวถึงในรายงานก็คือ
- เทคโนโลยี Data Lakehouse ได้ถูกออกแบบมาอย่างพิเศษเพื่อตอบโจทย์การจัดเก็บและวิเคราะห์ข้อมูล Log, Metric และ Trace ได้อย่างทันสมัย ผู้ใช้งานจะได้รับ Insight เกี่ยวกับสุขภาพและประสิทธิภาพของการทำงานอย่างมีคุณภาพ โดยเทคโนโลยีที่ชื่อว่า ‘Grail‘ นี่นำเสนอผ่านทางบริการแบบ SaaS
- Davis AI ได้ถูกออกแบบมาให้ค้นหาข้อมูลความเชื่อมโยงที่ได้จาก Smartscape ซึ่ง AI จะสามารถช่วยวิเคราะห์ข้อมูลได้อย่างอัตโนมัติ รวมถึงยังสามารถถูกเรียกใช้ได้แบบ On-demand ตามต้องการเพื่อศึกษาแนวโน้มการเปลี่ยนแปลงไปทำนายปัญหาด้านประสิทธิภาพ
- ทุกการออกแบบของระบบ Dynatrace ได้ถูกวางแผนมาอย่างดี มีการทำ HA ทุกส่วน รองรับการขยายตัวได้อย่างอัตโนมัติและใช้เทคนิคในการทำ Load balancing รวมถึงสตอเรจการจัดเก็บข้อมูลก็มีการทำ HA เช่นกัน
หากพิจารณาถึงคุณสมบัติที่ถูกการ์ทเนอร์นิยามเอาไว้ข้างต้น บอกได้เลยว่า Dynatrace นั้นตอบโจทย์เกือบทุกข้อ แม้กระทั่งความสามารถเสริมก็มีมาให้แล้ว นอกจากนี้ ความง่ายในการใช้งานและความชาญฉลาดอีกหลายประการทำให้ Dynatrace กลายเป็นเครื่องมือที่ผู้ประกอบการขนาดใหญ่ให้ความไว้วางใจ ซึ่งในบทความหน้าเราจะพาทุกท่านไปรู้จักกับ Dynatrace Observability ในมุมมองของ ITOps และ DevOps ตอนที่ 2 “ยกระดับงาน ITOps และ DevOps ด้วย AIOps ใน Observability Platform“
บทส่งท้าย
ในบทความนี้เราได้พาทุกท่านไปรู้จักกับความหมายของคำศัพท์ด้านไอทีตัวหนึ่งถูกใช้มานานแล้วอย่าง Monitoring ในขณะที่ Observability กำลังฉายแววความสำคัญ จากการที่เทคโนโลยีขององค์กรเผชิญกับความท้าทายในเรื่องของความซับซ้อนจนการอธิบายถึงต้นตอปัญหาเป็นเรื่องที่ทำได้ยาก นอกจากนี้เรายังแนะนำทุกท่านให้เข้าใจถึงความคล้ายคลึงกันระหว่าง APM และ Observability ที่แม้กระทั่งการ์ทเนอร์เองยังต้องรวมสองคำนี้ไว้ในการทำงานร่วมกัน ปิดท้ายกันด้วยเหตุผลที่การ์ทเนอร์ยกให้ Dynatrace เป็นเจ้าตลาดในปีการจัดอันดับตลาด APM & Observability ในปี 2023
ท่านใดสนใจศึกษาข้อมูลเพิ่มเติมได้ที่ https://www.dynatrace.com หรือติดต่อทีมงาน Dynatrace Thailand ได้ที่ https://www.dynatrace.com/contact/
ข้อมูลอ้างอิง