




คงเป็นเรื่องยากที่เราจะสร้างโมเดลของ Deep Learning ด้วยตัวเองตั้งแต่เริ่มต้นในเวลาอันจำกัด วันนี้เราได้พบกับเว็บไซต์ที่นำเสนอโมเดลด้าน Computer Vision ที่ถูกเทรนมาแล้วให้ผู้สนใจสามารถนำไปต่อยอดได้ โดยจะแบ่งเป็น 4 หมวด คือ Object Detection, Facial Recognition และ Regeneration, Segmentation และสุดท้าย Miscellaneous

Object Detection
1.Mask R-CNN เป็น Framework ที่ออกแบบมาสำหรับการตรวจจับวัตถุได้อย่างยืดหยุ่น โดยสร้างจาก Python และ Keras (Neural Network API) ซึ่งในโปรเจ็คนี้จะสร้างขอบของแต่ละวัตถุในภาพ (ดูภาพตัวอย่างด้านบน) สามารถติดตามได้ที่นี่ https://github.com/matterport/Mask_RCNN
2.YOLOv2 เป็นที่นิยมในการทำ Deep Learning อีกตัวหนึ่ง โดยสร้างได้จาก Keras เช่นกัน และมีการทดลองนำไปใช้กับงาน เช่น ตรวจเซลล์เม็ดเลือดแดง รถยนต์ขับเคลื่อนอัตโนมัติ แต่โมเดลที่ถูกเทรนไว้แล้วจะอยู่ในส่วนของการตรวจหาภาพของแรคคูน (สามารถดาวน์โหลดชุดข้อมูลภาพแรคคูนได้ ที่นี่ ) ผู้สนใจสามารถติดตามค่า Weight ของโมเดลได้ ที่นี่ เนื้อหาของโปรเจ็คบน GitHub อยู่ที่ https://github.com/experiencor/keras-yolo2

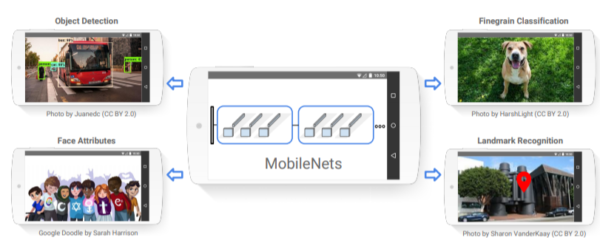
3.MobileNet เป็นโมเดลที่ถูกออกแบบมาสำหรับมือถือโดย Google นั่นเองโดยมาพร้อมกับ Weight ของโมเดลด้วยข้อมูลจากฐานข้อมูล ImageNet ที่ภายในรวบรวมภาพจำนวนหลายล้าน ซึ่งโมเดลนี้รองรับงานได้หลากหลาย (ดูจากภาพตัวอย่างด้านล่าง) สามารถติดตามได้ที่ https://keras.io/applications/#mobilenet
4.Ripe/Unripe Tomato Classification โปรเจ็คนี้ใช้ Deep Learning เพื่อหาว่ามะเขือเทศสุกหรือยัง โดยโมเดลนี้ถูกเทรนข้อมูลด้วยรูปภาพของมะเขือเทศที่กว่า 390 ภาพ ลองหาทดสอบได้ที่ https://github.com/fyrestorm-sdb/tomatoes

5.Car Classification หลายคนต้องสนใจโปรเจ็คนี้อยู่แน่ๆ คือการจำแนกรถโดยอาศัยภาพจาก Standford กว่า 16,185 ภาพจาก 196 ประเภท ติดตามได้ที่ https://github.com/michalgdak/car-recognition

Facial Recognition และ Regeneration
เราคงคุ้นเคยกับคำว่า Facial Recognition เพราะมันคือการจดจำใบหน้านั่นเองแต่เมื่อพูดถึง Regeneration ในส่วนนี้ทางผู้เขียนบทความต้นฉบับหมายถึงการสร้างโมเดล 3 มิติของหน้าจากรูปหน้าขึ้นมาใหม่ซึ่งเป็นความท้าทายอย่างยิ่ง เช่น อุตสาหกรรมภาพยนต์ หรือ เกม เป็นต้น

1.VGG-Face Model โมเดลนี้ถูกเทรนข้อมูลจาก VGG-Face ที่มีตัวตนหน้าอย่างมีลักษณะเฉพาะกว่า 2 ล้านรูป โดยการเทรนโมเดลถูกออกแบบตาม 2 ขั้นตอนคือ vgg-face-keras (การแปลงโมเดล vgg-face ไปยัง keras โมเดล) และ vgg-face-keras-fc (แปลงโมเดล vgg-face Caffe ไปยังโมเดล mxnet และแปลงไปยังโมเดล keras อีกทีหนึ่ง) ผู้สนใจสามารถติดตามได้ที่ https://gist.github.com/EncodeTS/6bbe8cb8bebad7a672f0d872561782d9
2.3D Face Reconstruction from a Single Image โมเดลนี้เริ่มแรกพัฒนาด้วย Torch (ดาวน์โหลดโปรเจ็คต้นฉบับ) และแปลงเป็น Keras อีกทีหนึ่งเพื่อสร้างหน้า 3 มิติจากรูปภาพ ติดตามได้ที่ https://github.com/dezmoanded/vrn-torch-to-keras

Segmentation

1.Semantic Image Segmentation – Deeplabv3+ ทางด้านเจ้าของบทความได้ให้ความหมายของคำว่า Semantic Image Segmentation หมายถึงการให้ความหมายของทุกพิเซลในภาพเพื่อแบ่งประเภทว่าเป็นวัตถุใด เช่น ท้องฟ้า รถยนต์ หรืออื่นๆ ในส่วนของ Deeplabv3+ คือโมเดลจาก Google ซึ่งต้นฉบับเป็น TensorFlow ที่ถูกสร้างเป็น Keras อีกทีหนึ่ง โดยบน GitHub มีวิธีการและขั้นตอนนำไปใช้อย่างละเอียด ติดตามได้ที่ https://github.com/bonlime/keras-deeplab-v3-plus
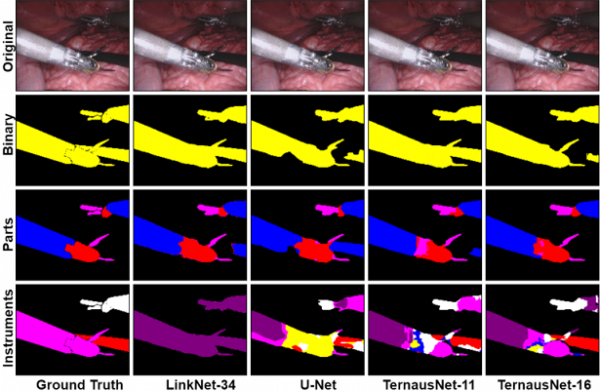
2.Robot Surgery Segmentation โมเดลนี้พยายามแก้ปัญหาการผ่าตัดโดยใช้หุ่นยนต์เข้ามาช่วย ซึ่งปัญหาแบ่งเป็น 2 ส่วนคือ ต้องแยกแยะระหว่างเครื่องมือและพื้นหลัง อีกส่วนหนึ่งคือการแยกแยะเครื่องมือหลายส่วน ตัวโมเดลนี้ถูกเทรนด้วยเฟรมความละเอียดสูงของระบบภาพ 3 มิติ สามารถติดตามได้ที่ https://github.com/ternaus/robot-surgery-segmentation
Miscellaneous
Image Captioning เป็นการผสานระหว่าง NLP และ Computer Vision ซึ่งความยากคือต้องการชุดข้อมูลขนาดใหญ่ที่ต้องไม่เอนเอียงไปทางใดทางหนึ่งด้วย ดังนั้นโซลูชันนี้จึงใช้การป้อนรูปภาพและคำอธิบายที่มีความหมายสั้นๆ โดยส่วนของ Encoder ที่ใช้คือ CNN นั่นเอง ส่วนฝั่ง Decoder คือการใช้ long Short-term memory network (LSTM) เพื่อทำนายคำอธิบายของรูปสามารถติดตามได้ที่ https://github.com/boluoyu/ImageCaption

ที่มาและเครดิตรูปภาพ : https://www.analyticsvidhya.com/blog/2018/07/top-10-pretrained-models-get-started-deep-learning-part-1-computer-vision/








