




Linux เป็นระบบปฏิบัติการที่มีความยืดหยุ่นเป็นอย่างมาก โดยมีกลไกที่ช่วยให้ผู้ดูแลระบบสามารถปรับจูนประสิทธิภาพได้หลายช่องทาง มีการเปิดเผยซอร์สโค้ดให้สามารถเข้าไปศึกษาทำความเข้าใจการทำงานภายในได้ ด้วยเหตุนี้ Linux จึงเป็นระบบปฏิบัติการที่ผู้ดูแลระบบประสบการณ์สูงมักเลือกใช้ ทั้งยังมีความสเถียรอีกด้วย
ในบทความนี้เราจะพาทุกท่านมารู้จักกับคำว่า ‘Swappiness’ ในระบบปฏิบัติการ Linux ให้มากขึ้น ซึ่งมักถูกเข้าใจผิดว่าเป็นตัวช่วยหลักสำหรับการเพิ่มประสิทธิภาพ แต่อันที่จริงแล้วอาจไม่ได้มีผลโดยตรงตามที่คาดหวัง และหากมีอัตราใช้ไม่เหมาะสม ยังอาจนำไปสู่การลดทอนประสิทธิภาพการทำงานได้อีกด้วย
การทำงานของ Memory ฉบับ 101
ก่อนที่จะเข้าเรื่อง Swappiness ที่เป็นตัวช่วยในการบริหารจัดการหน่วยความจำ (Memory) หรือ RAM เป็นไปไม่ได้เลยที่เราจะข้ามความรู้ในเรื่องโครงสร้างการทำงานของ Memory
1. หน่วยความจำในระบบปฏิบัติการมีอยู่ 2 ส่วน คือ Physical Memory ที่อ้างถึงตามศักยภาพของฮาร์ดแวร์(RAM) ที่ท่านมีซึ่งจะถูกเก็บข้อมูล คำสั่ง ระหว่างการประมวลผลโปรแกรม แต่มีอีกคอนเซปต์หนึ่งที่ถูกตระเตรียมโดย OS สำหรับให้โปรแกรมอ้างถึงได้ที่เรียกว่า Virtual Memory โดยที่ไม่ได้ขึ้นต่อกัน ทั้งนี้ OS จะมีกลไกการจับคู่ระหว่างพื้นที่ทั้งสองรูปแบบที่เรียกว่า ‘Memory Mapping’ ซึ่งประโยชน์ของการมี Virtual Memory ก็คือช่วยในการบริหารจัดการหน่วยความจำ และหนึ่งในกลไกที่ช่วยย้ายข้อมูลใน Memory ไปไว้ใน Storage ลำดับชั้นถัดไปเช่น ฮาร์ดดิสก์หรืออื่นๆ เรียกว่า ‘Swapping’
2. RAM มีคอนเซปต์การแบ่งส่วนออกเป็นโซนต่างๆ โดยมุมมองของสถาปัตยกรรมแบบ 32 บิต และ 64 บิตก็จะมีความแตกต่างกัน ซึ่งหากอ้างอิงถามสถาปัตยกรรมของ x86 จะมีโซนของ
- Direct Memory Access (DMA) – เป็นชื่อที่ถูกตั้งเมื่อนานมาแล้ว สมัยที่คอมพิวเตอร์สามารถเข้าถึง Physical Memory โดยตรงในส่วนที่มี 16 MB ล่าง แต่ในกรณีของเครื่องแบบ 64 บิตจะมีคำว่า Direct Memory Access 32 ที่มองส่วน 4 GB ล่าง ในขณะที่เครื่องแบบ 32 บิตจะมองส่วนนี้ว่าเป็น HighMem
- Normal – พื้นที่เหนือ 4GB สำหรับเครื่องแบบ 64 บิต กลับกันในเครื่องแบบ 32 บิตคือช่วงระหว่าง 16MB และ 896 MB
- HighMem – มีเฉพาะเครื่องแบบ 32 บิตคือส่วนที่เหนือกว่า 896 MB
3. Virtual Memory ถูกแบ่งเป็นสัดส่วนที่มีขนาดเท่ากันแบบคงที่ที่เรียกว่า Pages ซึ่งจะเป็นหัวใจสำคัญที่ช่วยในการบริการจัดการหน่วยความจำและเนื้อเรื่องของ Swappiness ในครั้งนี้ โดยขนาดของ Pages จะถูกกำหนด ณ ขณะบูตเครื่อง ซึ่งปกติแล้วระบบ Linux จะกำหนดขนาดไว้ที่ 4 Kbytes(4,096 Bytes) อย่างไรก็ตาม Pages เองก็มีการจัดแบ่งออกเป็นหลายชนิดดังนี้
- Code – ส่วนจัดเก็บคำสั่งของโปรแกรม โค้ดของเครื่อง โดยมีคุณสมบัติอ่านได้เท่านั้น (R only) เพื่อป้องกันการเปลี่ยนแปลง โดยกลุ่มโปรเซสในโปรแกรมเดียวกันจะแชร์ Code Pages ร่วมกันเพื่อความมีประสิทธิภาพ
- Data – เก็บข้อมูลที่ไม่ได้ถูกโปรแกรม Execute เช่น ตัวแปร, Constant, Data Structure ซึ่ง Data Pages สามารถถูกเขียนได้ตามต้องการ โดยแต่ละโปรเซสจะมี Data Pages เป็นของตัวเองไม่ใช้ร่วมกัน
- Stack – จัดเก็บข้อมูลแบบ Dynamic มีความเคลื่อนไหว โดยก็คือช่วยในการจดจำ Local Variable ของฟังก์ชัน ซึ่งทำงานแบบ Last in First out (LIFO) ลองจิตนาการถึงการทำงานแบบฟังก์ชันซ้อนฟังก์ชัน หรือ Recursive ดูสิ
- Heap – เก็บการใช้พื้นที่ของฟังก์ชัน เช่น malloc() และ free() เป็นต้น โดยมีกำหนดขนาดและเวลา ทั้งนี้ข้อมูลต้องถูกปลดปล่อย (deallocate()) เพื่อป้องกันการเกิดปัญหา memory leaks
- Share Memory – เก็บข้อมูลระหว่างโปรเซสช่วยให้เกิดการอ่านเขียนได้โดยตรงเพิ่มประสิทธิภาพการทำงานร่วมกันระหว่างโปรเซส (inter-process communication)
- Anonymous (Private pages) – เก็บข้อมูลที่ถูกจองใช้ระหว่าง Runtime เช่น ตัวแปร หรือข้อมูลต่างๆ ทั้งนี้ไม่เชื่อมโยงกับไฟล์หรือข้องเกี่ยวกับพื้นที่จัดเก็บแบบถาวรใดๆ
- File-backed – เชื่อมโยงโดยตรงกับไฟล์บนดิสก์ โดยเก็บข้อมูลที่ถูกอ่านมาจากไฟล์ชนิดใดๆ การเปลี่ยนแปลงใดๆที่ Memory จะต้องถูกเขียนลงไฟล์ก่อนที่พื้นที่บน Memory จะถูกปลดปล่อย กล่าวคือช่วยในการทำ Memory Mapping File และ Virtual Memory ของโปรเซส
Swappiness คืออะไรกันแน่?
มาถึงตรงนี้เราทราบแล้วว่า RAM มีมุมมองการแบ่งส่วนย่อย และมีคอนเซปต์เรื่อง Virtual Memory ที่มี Pages ชนิดต่างๆ ช่วยสนับสนุนในการบริหารจัดการพื้นที่ในหน่วยความจำได้อย่างคล่องตัว โดยยังมีอีกหนึ่งคำศัพท์ที่ต้องกล่าวถึงคือ Swapping หรือเทคนิคที่ช่วยเขียนข้อมูลของ RAM มายังพื้นที่หนึ่งบนฮาร์ดดิสก์(Swap Space ตามภาพประกอบ)เพื่อช่วยลดพื้น RAM แล้วค่อยนำข้อมูลกลับมาเมื่อโปรเซสที่ใช้พื้นที่บน RAM เสร็จสิ้น โดย Swap space เป็นเรื่องที่มีการกำหนดขนาดไว้อย่างแน่นอน อย่างไรก็ตาม Swappiness ไม่ได้มีบทบาทในการกำหนดพื้นที่นี้แต่อย่างใดและไม่ได้เป็นการกำหนด Threshold อัตราการใช้งาน RAM ที่จะเกิดการ Swapping ด้วย
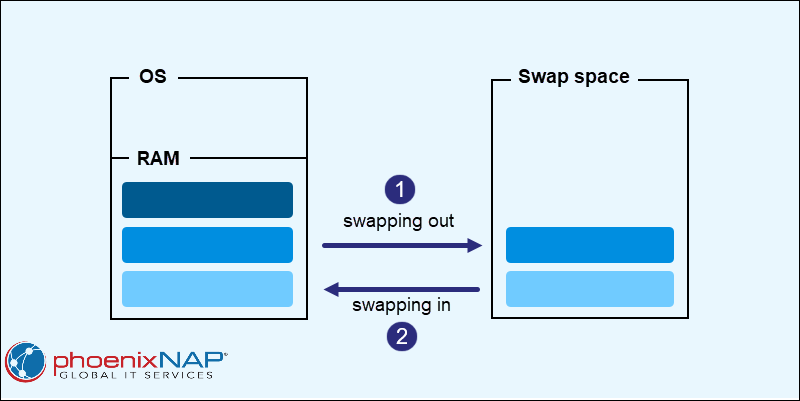
Swappiness เป็นเพียงพารามิเตอร์ตัวหนึ่งใน Linux Kernel ที่มีอิทธิพลในความบ่อยครั้งของการ Swapping ของ Anonymous Pages และ file-backed ซึ่งต้องมีการเลือกผลประโยชน์ระหว่างอย่างใดอย่างหนึ่ง โดย Swappiness จะมีค่าระหว่าง 0 ถึง 200 และเริ่มต้นพื้นฐานที่ 60
ทั้งนี้ Swappiness หมายถึงการกำหนดความเข้มข้นในการ Swapping เท่านั้น แม้กระทั่งค่า 0 ก็ยังเกิดการ Swapping เมื่อเข้าเงื่อนไขหนึ่ง หากกำหนดค่าเป็น maximum หมายถึงให้ความสำคัญของ Anonymous และ file-backed เท่ากัน กล่าวคือเป็นเพียงรักษาอัตราความสำคัญในการ Swapping ระหว่าง Pages 2 ชนิด ซึ่งไม่มีหลักการตายตัวแต่สามารถปรับให้เหมาะสมกับงานได้ เช่น
- ถ้าคุณมี Physical Memory มากเก็บข้อมูลใน RAM ได้เหลือเฟือ หรือฮาร์ดไดร์ฟเก่าที่ล่าช้า หากลดการข้องเกี่ยวกับ I/O คงจะดีกว่า ซึ่งทำได้ด้วยการปรับลดค่า Swappiness
- กลับกันถ้า RAM น้อยและ Workload สามารถได้ประโยชน์จากการ Swap บ่อยครั้ง ก็เพิ่มค่า Swappiness ได้
คำสั่งเกี่ยวกับ Swappiness ใน Linux
ท่านสามารถตรวจสอบค่า Swappiness ใน OS ของท่านใดด้วยคำสั่ง
/proc/sys/vm/swappiness หรือ sysctl vm.swappiness
แก้ไขค่า swappiness ด้วยคำสั่ง
sudo sysctl vm.swappiness=[value]
กำหนดค่าให้อยู่ถาวรไม่หายเมื่อรีบูตได้ด้วย
nano /etc/sysctl.conf และ vm.swappiness = [value]
การปรับจูนค่า Swappiness ไม่มีเกณฑ์กลางแต่เป็นเรื่องที่ผู้ดูแลระบบต้องทดสอบและเฝ้าสังเกตประสิทธิภาพอย่างต่อเนื่อง อย่างไรก็ดีโดยปกติแล้วท่านอาจอ้างอิงตามคำแนะนำจาก Vendor ใน Database บางตัว แต่ส่วนใหญ่มักมีกลไกภายในของตัวเองที่ดีอยู่แล้ว ซึ่งแน่นอนว่าหากเป็นผู้ใช้งานทั่วไปก็เพียงแค่รู้ไว้ก็ว่า “Swappiness ไม่ใช่กลไกป้องกัน Memory เต็มแต่อย่างใด แต่หากไม่มีกลไกนี้ก็คงยากมากสำหรับ Linux ที่จะบริหารจัดการ Memory ให้ดีได้”
ที่มา : https://phoenixnap.com/kb/swappiness และ https://www.howtogeek.com/449691/what-is-swapiness-on-linux-and-how-to-change-it/




