




ดูเหมือนว่า Meta จะอยากเปิดตัวโมเดล AI ที่ล้อไปกับเทศกาลฮาโลวีนที่กำลังจะถึงในเร็ว ๆ นี้ โดยได้เปิดตัว Meta Spirit LM โมเดล Multimodal ใหม่ให้เป็น Open Source ที่สามารถใส่อารมณ์หรือโทนเสียง ทำให้เชื่อมโยงข้อความและเสียงที่เป็น Input และ Output ได้อย่างไร้รอยต่อมากยิ่งขึ้น

ล่าสุด Meta ได้เปิดตัว Meta Spirit LM โมเดล Multimodal ที่จะไปแข่งขันกับคู่แข่งเจ้าอื่น ๆ อย่าง GPT-4o ของ OpenAI หรือว่า EVI 2 ของ Hume หรือว่า ElevenLabs ที่มีความเชี่ยวชาญในการแปลงเสียงเป็นข้อความ (Speech-To-Text หรือ Automatic Speech Recognition หรือ ASR) และแปลงข้อความเป็นเสียง (Text-To-Speech หรือ TTS) โดยเฉพาะ
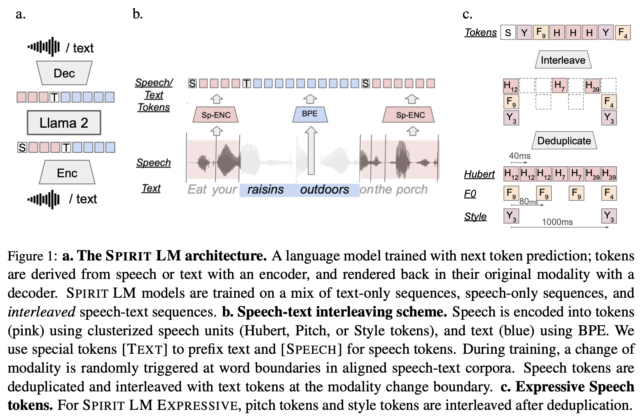
Meta Spirit LM นี้ถูกออกแบบและพัฒนาโดยทีม Fundamental AI Research (FAIR) แห่ง Meta ซึ่งโมเดลดังกล่าวต้องการที่จะแก้ไขข้อจำกัดที่มีอยู่ในการสังเคราะห์หรือว่าสร้างเสียงให้มีความเป็นธรรมชาติ และมีการแสดงออกในอารมณ์ที่ต้องการได้มากขึ้น ด้วยการเรียนรู้การทำ ASR, TTS และ Speech Classification ได้พร้อม ๆ กัน
โดย Meta ได้ปล่อย Spirit LM ออกมา 2 เวอร์ชัน ได้แก่
- Spirit LM Base ที่ใช้ Token ของโฟเนติก (Phonetic) หรือการออกเสียงในการประมวลผลและสังเคราะห์เสียงพูด
- Spirit LM Expressive ที่จะมี Token เพิ่มสำหรับเรื่องพิตช์ (Pitch) และโทน (Tonee) ที่จะให้โมเดลสามารถจับอารมณ์ เช่น ตื่นเต้นหรือว่าเศร้า เพื่อให้สะท้อนสิ่งเหล่านั้นเข้าไปในเสียงที่สังเคราะห์ขึ้นมาได้
อย่างไรก็ดี ณ วินาทีนี้โมเดล Meta Spirit LM ยังไม่ได้อนุญาตให้ใช้งานได้ในเชิงพาณิชย์ ซึ่งอนุญาตให้ทดลองนำไปใช้สำหรับงานวิจัยที่ต่อยอดจากโมเดล Open Source ดังกล่าวนี้เท่านั้น สำหรับรายละเอียดเกี่ยวกับ Spirit LM สามารถอ่านและฟังตัวอย่างเสียงเพิ่มเติมได้ที่นี่










