




ทีมงาน TechTalkThai มีโอกาสได้มาร่วมงานสัมมนา Accelerated AI and Data Science with Cloud Agility ซึ่งจัดขึ้นโดยทางทีมงาน IBM Thailand สำหรับอัปเดตเทคโนโลยีทางด้าน Information Architecture และเปิดตัวโซลูชันล่าสุด IBM Cloud Private for Data เพื่อให้องค์กรสามารถตอบรับต่อการทำ Big Data และ AI ได้อย่างมีประสิทธิภาพ พร้อมทั้งอัปเดตแนวโน้มทางด้านธุรกิจที่เริ่มมีการแข่งขันในรูปแบบที่เปลี่ยนไป ซึ่งทางทีมงาน TechTalkThai ก็ขอสรุปเนื้อหาต่างๆ เอาไว้สำหรับผู้อ่านทุกท่านดังนี้ครับ
Digital Transformation เปลี่ยนจากการแข่งขันกับธุรกิจ Startup มาสู่การแข่งขันในระดับธุรกิจองค์กรด้วยกันเอง
IBM ได้ระบุว่าการพูดถึง Disruption กลายเป็นเรื่องใกล้ตัวขึ้นเรื่อยๆ หลายองค์กรต้องปรับตัว หลายๆ องค์กรมีคำถามว่าสิ่งที่ธุรกิจของตนเองทำอยู่นั้นดีหรือยัง และจะนำเทคโนโลยีใหม่ๆ อย่าง AI มาใช้งานได้อย่างไร
ปัจจุบันข้อมูลมีปริมาณมหาศาลมากบนโลก และมีเพียงแค่ประมาณ 20% เท่านั้นที่สามารถค้นหาได้ผ่าน Search Engine ส่วนข้อมูลอีกกว่า 80% ที่เหลือนั้นก็อยู่ภายในการใช้งานส่วนตัวและภายในธุรกิจองค์กรต่างๆ ซึ่งข้อมูลเหล่านี้ก็ถือเป็นทรัพย์สินของธุรกิจ และนำไปใช้ในการแข่งขันได้อีกทางหนึ่ง
ปัจจุบันนี้เหล่าธุรกิจองค์กรนั้นไม่ได้มีเพียงแต่ Startup ที่ต้องจับตามองและแข่งขันแล้ว เนื่องจากยอดการลงทุนในธุรกิจ Startup ในสหรัฐอเมริกานั้นก็หดตัวลงเป็นอย่างมาก แต่เหล่าธุรกิจขนาดใหญ่ที่เริ่มขยับตัวนั้นกลับน่ากลัวยิ่งกว่า เพราะมีทั้งงบประมาณและข้อมูลพร้อมสำหรับใช้ในการแข่งขัน และสิ่งที่เหล่าธุรกิจควรจะต้องทำก็คือการเตรียมความพร้อมรับมือต่อการเปลี่ยนแปลงที่จะเกิดจากเหล่าธุรกิจขนาดใหญ่ที่เริ่มขยับตัวอย่างรุนแรง
Information Architecture for AI Strategy: เมื่อ AI และ Big Data ไม่อาจแยกขาดจากกันได้
- 99% ของเหล่าธุรกิจต้องการมุ่งไปสู่การทำงานแบบ Insight-driven แต่มีเพียง 1 ใน 3 เท่านั้นที่ประสบความสำเร็จ
- ภายในปี 2019 40% ของการทำ Digital Transformation จะมีการใช้บริการระบบ AI
- ภายในปี 2021 75% ของ Application ในระดับองค์กร จะมีการใช้งาน AI
- ลูกค้าจะโต้ตอบกับธุรกิจผ่านทาง Chatbot มากกว่า 50%
- มากกว่า 50% ของหุ่นยนต์ในอุตสาหกรรมจะมีการใช้งาน AI เป็นเบื้องหลัง
บทบาทของ AI ในอนาคตก็คือการที่ AI จะได้เรียนรู้ในสิ่งที่มนุษย์ต้องการจะนำ AI มาช่วยงาน เพื่อให้บุคลากรภายในธุรกิจองค์กรต่างๆ สามารถทำงานได้อย่างมีประสิทธิภาพมากยิ่งขึ้น ดังนั้นบทบาทหลักของเหล่าธุรกิจองค์กรในปัจจุบันนี้จึงแบ่งออกเป็นการมองหาบทบาทของ AI ที่จะมาช่วยเสริมธุรกิจขององค์กรได้ และการเสริมทักษะของบุคลากรให้สามารถใช้งาน AI ได้อย่างมีประสิทธิภาพ และในการก้าวไปสู่ปลายทางดังกล่าว องค์กรก็ต้องเริ่มต้นจากการทำความเข้าใจขอบเขตของเทคโนโลยีให้ดีเสียก่อนว่า AI ทำอะได้ได้มากน้อยแค่ไหน และธุรกิจของเรามีข้อมูลอะไรอยู่บ้างสำหรับพร้อมใช้งาน
ปัจจุบัน IBM ในประเทศไทยเองก็ได้มีบทบาทในการเข้าไปให้คำแนะนำแก่เหล่าธุรกิจองค์กรทั้งเอกชนและภาครัฐในโครงการด้านระบบ Big Data และทาง IBM เองก็ได้เริ่มเห็นถึงแนวโน้มที่เหล่าองค์กรต่างๆ เริ่มมองไกลไปถึงการนำ AI มาใช้ในการช่วยวิเคราะห์ข้อมูลให้มีความเป็นอัตโนมัติมากยิ่งขึ้น และตอบโจทย์ภาคธุรกิจได้ดียิ่งขึ้นไปพร้อมๆ กัน พร้อมกับทิ้งคำกล่าวที่ชวนคิดเอาไว้ว่า “Big Data without AI is a Big Headache.”
สำหรับสิ่งที่ AI สามารถทำได้ดีในปัจจุบัน มีดังนี้
- Locating Knowledge ระบบ Search Engine เพื่อค้นหาข้อมูลต่างๆ ทั้งภายในและภายนอกองค์กร
- Pattern Identification การจำแนกรูปแบบของการทำธุรกรรมและการตลาดรวมถึงการนำไปใช้งานในแผนกอื่นๆ เพื่อค้นหาโอกาสใหม่ๆ ในการทำธุรกิจ หรือการปรับปรุงธุรกิจให้มีประสิทธิภาพมากขึ้น เช่น การค้นหารูปแบบสิ่งที่ลูกค้าของธุรกิจต้องการ เป็นต้น
- Natural Language วิเคราะห์ภาษาสื่อสารที่ใช้งานกันโดยธรรมชาติ เพื่อทำความเข้าใจเนื้อหาที่มีการสื่อสาร
- Machine Learning วิเคราะห์ข้อมูลเพื่อค้นหารูปแบบสำหรับนำมาใช้ในการทำนายหรือจำแนกกลุ่มและประเภทของสิ่งต่างๆ
- Eliminate Bias ทำการวิเคราะห์และนำเสนอข้อมูลโดยปราศจาก Bias จากมนุษย์
- Endless Capacity การวิเคราะห์ข้อมูลปริมาณมหาศาลได้อย่างรวดเร็ว
องค์กรควรเริ่มโครงการ AI และ Big Data จากโจทย์ขนาดเล็กๆ ก่อนเพื่อให้ธุรกิจมีความรู้ความเข้าใจในเทคโนโลยี และเริ่มเห็นผลลัพธ์จากการนำเทคโนโลยีมาใช้อย่างได้ผล เพื่อให้ในอนาคตการลงทุนในโครงการด้าน AI และ Big Data ต่อไปนั้นมีทิศทางที่ชัดเจนมากยิ่งขึ้นและเลือกใช้เทคโนโลยีได้อย่างเหมาะสมมากยิ่งขึ้นต่อไป
มีเพียง 20% ของโครงการ Data Science ในธุรกิจองค์กรเท่านั้นที่ประสบความสำเร็จ
ทาง IBM ได้นำเสนอถึง 4 ลำดับขั้นตอนพื้นฐานของโครงการ Data Science เอาไว้ดังนี้
- Gather All Data รวบรวมข้อมูล
- Prepare Data แปลงข้อมูลให้อยู่ในรูปที่พร้อมใช้งานได้
- Machine Learning Pattern Identification สร้างโมเดลการวิเคราะห์รูปแบบต่างๆ ที่เกิดขึ้นในข้อมูล
- Evaluate Test Model ทดสอบโมเดลที่สร้างขึ้นมาเพื่อตรวจสอบความแม่นยำ
กระบวนการเหล่านี้เป็นกระบวนการที่ต้องทำซ้ำอย่างต่อเนื่องเพื่อให้ระบบมีความแม่นยำมากยิ่งขึ้น ไม่ว่าจะเนื่องจากการเรียนรู้ข้อมูลใหม่ๆ เพิ่มเติม, การทดสอบกับข้อมูลตัวอย่างที่กว้างยิ่งกว่าเดิม ไปจนถึงการปรับเปลี่ยนโมเดลที่ใช้ในการเรียนรู้เพื่อให้ตรงต่อวัตถุประสงค์มากยิ่งขึ้น
อย่างไรก็ดี กว่า 80% ของเวลาที่ใช้ในการทำโครงการคือการรวบรวมข้อมูลจากหลากหลายแหล่งและนำมาแปลงให้อยู่ในรูปที่พร้อมนำไปใช้งานได้ ซึ่งขั้นตอนเหล่านี้ก็ถือเป็นขั้นตอนที่ทำให้เหล่าผู้เชี่ยวชาญต้องเสียเวลาเป็นอย่างมากกว่าที่โครงการใดๆ จะเริ่มต้นและทำงานได้จริง ด้วยปัจจัยต่างๆ ทั้งข้อมูลที่เก่าเกินไป, ข้อมูลที่ไม่ครบถ้วน และอื่นๆ อีกมากมาย ซึ่งสิ่งเหล่านี้สามารถถูกแก้ไขและทำให้เป็นอัตโนมัติได้ด้วยเครื่องมือต่างๆ และเทคโนโลยี AI
IBM ได้นำเสนอแนวโน้มอีกว่ามีเพียง 20% ขององค์กรเท่านั้นที่นำ AI ไปใช้งานจริงได้ประสบความสำเร็จ ทั้งนี้ก็เป็นเพราะขั้นตอนในการสร้าง Information Architecture หรือ IA ที่เหมาะสมและรองรับต่อการทำ AI ได้ดีนั้นถือเป็นหัวใจสำคัญ เพราะ AI จะไม่สามารถขับเคลื่อนธุรกิจองค์กรได้อย่างมีประสิทธิภาพเลย หากระบบการจัดการข้อมูลขององค์กรนั้นยังคงเป็นคอขวดของธุรกิจอยู่
IBM ได้สรุปถึง 2 ปัจจัยหลักที่ทำให้โครงการด้าน Data Science และ AI ดำเนินไปได้อย่างเชื่องช้าหรือไม่ประสบความสำเร็จ ดังนี้
- ไม่รู้ว่า AI เก่งตรงไหน ทำให้ไม่สามารถขึ้นโครงการที่ใช้ AI เพื่อตอบโจทย์ได้อย่างรวดเร็ว
- ระบบจัดการข้อมูลไม่มีประสิทธิภาพ Data Scientist ไม่สามารถทำงานได้
- ข้อมูลไม่ได้ถูกจัดเก็บอย่างเป็นระบบ เข้าถึงได้ยาก
- มีเครื่องมือในการวิเคราะห์ที่หลากหลายเกินไป ดูแลยาก ถ่ายทอดความรู้ได้ยาก
- ไม่มีกระบวนการการใช้งานและวิเคราะห์ข้อมูลที่เป็นมาตรฐาน
- ขาดวัฒนธรรมองค์กรที่ดีในการทำงานร่วมกันระหว่างแผนกเพื่อแลกเปลี่ยนข้อมูล ไปจนถึงการไม่เชื่อมั่นในเทคโนโลยี AI
Hybrid Data Lake Architecture การเลือกใช้เทคโนโลยีสำหรับจัดเก็บข้อมูลให้เหมาะสม ก็เป็นอีกหัวใจที่สำคัญ
อีกหนึ่งประเด็นน่าสนใจที่ IBM พูดถึงก็คือการที่ข้อมูลที่อยู่ในองค์กรนั้นมีรูปแบบที่หลากหลาย และการนำไปใช้งานก็มีความแตกต่างกัน ดังนั้นการเลือกใช้เทคโนโลยีที่เหมาะสมต่อสองปัจจัยนี้ก็จะเป็นสิ่งที่ช่วยเพิ่มโอกาสสำเร็จของการทำโครงการด้าน Data Science และ AI และประเด็นนี้ก็ไม่ได้มีสูตรสำเร็จที่ตายตัว เพราะแต่ละธุรกิจองค์กรนั้นก็มีความแตกต่างกัน
IBM ได้นำเสนอแนวคิดของ Hybrid Data Lake Architecture ที่นำเทคโนโลยี Data Virtualization เข้ามาช่วยเพื่อให้สามารถใช้งานเทคโนโลยีได้อย่างหลากหลายในการจัดเก็บและจัดการเข้าถึงข้อมูลรูปแบบต่างๆ โดยเฉพาะอย่างยิ่งบรรดาเทคโนโลยี Open Source Software ที่มีบทบาทเป็นอย่างมากในวงการนี้ และปรับเปลี่ยนเทคโนโลยีให้เหมาะสมต่อความต้องการใหม่ๆ ในการนำข้อมูลไปใช้งาน
แน่นอนว่าอีกปัจจัยที่สำคัญก็คือการเสริมสร้างทักษะให้กับเหล่าผู้ดูแลระบบ IT และผู้ดูแลข้อมูล เพราะแทบทุกเทคโนโลยีถือเป็นเทคโนโลยีใหม่สำหรับเหล่าองค์กรทั้งสิ้น และการมีองค์ความรู้ในเชิงลึกเกี่ยวกัเทคโนโลยีเหล่านี้เองก็จะช่วยให้องค์กรสามารถเลือกใช้งานเทคโนโลยีได้อย่างเหมาะสม
นำ Agile มาใช้กับการจัดการข้อมูล: ใช้ Microservices ตอบโจทย์

IBM ได้เล่าถึงโซลูชัน IBM ICP4Data ที่ IBM ได้เปลี่ยนสถาปัตยกรรมภายในให้เป็นแบบ Microservices ทั้งหมดในการบริหารจัดการข้อมูลบน Private Cloud และ Public Cloud เพื่อให้เหล่าองค์กรมีความยืดหยุ่นในการเลือกใช้เทคโนโลยีที่เหมาะสมกับข้อมูล และเพิ่มขยายประสิทธิภาพเฉพาะส่วนได้ตามต้องการ อีกทั้งยังครอบคลุมไปถึงการตรวจสอบประสิทธิภาพการทำงานและการแก้ไขปัญหาทั้งหมดได้อย่างง่ายดาย
เทคโนโลยีหลักในระบบนี้ก็คือการนำ Kubernetes มาใช้ในการจัดการกับ Container ของบริการต่างๆ ที่เกี่ยวข้องในการจัดการกับข้อมูล ซึ่งนอกจากจะตอบโจทย์ด้านการแปลงสถาปัตยกรรมให้กลายเป็น Microservices เพื่อให้ได้มาซึ่งความยืดหยุ่นในการเลือกใช้และจัดการกับเทคโนโลยีต่างๆ แล้ว ก็ยังเป็นก้าวสำคัญในการนำองค์กรไปสู่กลยุทธ์ Multi-Cloud ด้วยในตัว
Container: เทคโนโลยีที่จะมาพลิกโฉมโลก Data Center ขององค์กร
เพื่อขยายความถึงข้อดีของการนำ Microservices มาใช้งาน ทาง IBM ได้เล่าถึงข้อดีของการนำเทคโนโลยี Container มาใช้งานดังนี้
- สามารถทำ Continuous Delivery อัปเดตและแก้ไข Software ต่างๆ ได้อย่างต่อเนื่อง
- เพิ่มความมั่นคงปลอดภัยให้กับระบบ ด้วยการลดความซับซ้อนและส่วนประกอบในแต่ละ Container ให้เหลือน้อยลง ง่ายต่อการจัดการด้านความมั่นคงปลอดภัย
- ทำงานได้บนทุกเทคโนโลยี ไม่ติดปัญหาด้านความแตกต่างของสภาพแวดล้อมภายในระบบอีกต่อไป
- ทำงานได้เหมือนกันบนทุกที่ ลดโอกาสการเกิดบั๊กในขั้นตอนการพัฒนา ทดสอบ และใช้งานจริงลง
การนำสถาปัตยกรรม Microservices มาใช้งานนี้จะนำองค์กรไปสู่การพัฒนา Cloud Native Application ที่แยกบริการย่อยต่างๆ ภายในระบบออกเป็น Microservices และแยกฐานข้อมูลออกเป็นหลายๆ ระบบสำหรับรองรับแต่ละ Microservices แยกกันไป ในขณะที่มีระบบบริหารจัดการจากศูนย์กลางและมีหน้าจอการใช้งานที่เชื่อมต่อบริการย่อยต่างๆ เข้าด้วยกัน
Kubernetes ที่จะเป็นเทคโนโลยีหลักในการบริหารจัดการ Container จาก Docker นี้ก็คือโครงการ Open Source Software ที่ IBM เลือกใช้ ด้วยความสามารถต่างๆ ที่หลากหลายดังนี้
- Intelligent Scheduling การเลือกใช้ทรัพยากรในระบบต่างๆ อย่างชาญฉลาด เพื่อให้ระบบต่างๆ สามารถทำงานได้อย่างเต็มประสิทธิภาพและทนทาน
- Self Healing การตรวจสอบการทำงานของ Container เพื่อให้มั่นใจว่าบริการต่างๆ สามารถทำงานได้อยู่เสมอ และซ่อมแซมตนเองได้เมื่อระบบใดหยุดทำงาน รวมถึงให้ Container อื่นๆ ทำงานทดแทนระบบส่วนที่หยุดทำงานไป
- Horizontal Scaling สามารถเพิ่มขยายระบบเพื่อเสริมประสิทธิภาพในการประมวลผลได้อย่างง่ายดาย
- Service Discovery and Load Balancing สามารถจัดการตั้งค่าการเชื่อมต่อและการทำงานทดแทนในแต่ละ Microservices ได้ด้วนตนเอง
- Automated Rollout and Rollback สามารถทำการแก้ไขเปลี่ยนแปลงส่วนต่างๆ ของระบบให้เป็นโค้ดชุดใหม่ได้ และทำการเปลี่ยนระบบกลับหากพบว่ามีปัญหาได้
- Secret and Configuration Management สามารถจัดการกับกุญแจเข้ารหัสและการตั้งค่าของแต่ละ Container หรือ Service ที่ใช้งานได้
ใน Kubernetes นั้นเราจะทำการสร้าง Pod ขึ้นมาสำหรับแต่ละ Microservices เพื่อให้การ Deploy สามารถทำงานได้อย่างง่ายดาย และกำหนดปริมาณของ Container ที่ต้องการสร้างขึ้นมาทำงานได้อย่างยืดหยุ่น และลดความผิดพลาดในการติดตั้งระบบหรือเริ่มต้นใช้งานด้วยการนำแนวคิดของ Infrastructure-as-Code มาใช้ ซึ่งในระบบขนาดใหญ่เองก็จะประกอบด้วยหลาย Pod ที่ทำงานร่วมกันเพื่อเกิดเป็นภาพรวมของบริการหนึ่งๆ ขึ้นมา
IBM Cloud Private for Data: โซลูชันระบบ Private Cloud สำหรับการจัดการข้อมูล

จะเห็นได้ว่าการออกแบบระบบ Information Architecture ที่ดีนั้นจะต้องประกอบไปด้วยองค์กรประกอบต่างๆ มากมายรวมถึงต้องมีการใช้งานโครงการ Open Source Software ต่างๆ ที่หลากหลาย ทำให้การออกแบบ ติดตั้ง และดูแลรักษาระบบเหล่านี้ไม่ใช่เรื่องง่าย และหลายๆ ครั้งก็กลายเป็นคอขวดที่ทำให้องค์กรไม่ประสบความสำเร็จในโครงการด้าน Big Data และ AI ซึ่ง IBM เองก็ต้องการตีโจทย์เหล่านี้เพื่อให้เหล่าองค์กรสามารถก้าวไปสู่ขั้นถัดไปในการทำ Digital Transformation ด้วยการนำข้อมูลมาใช้ในการทำธุรกิจอย่างมีประสิทธิภาพให้ได้
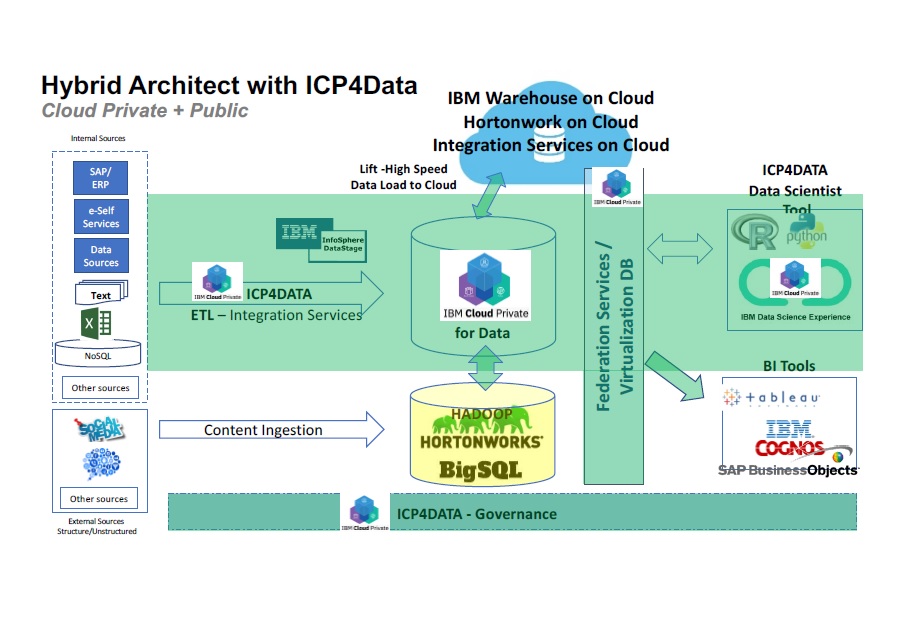
เพื่อให้เหล่าองค์กรมีระบบ Infrastructure สำหรับการจัดการข้อมูลที่เหมาะสมและก้าวไปสู่การใช้งาน AI ได้อย่างมีประสิทธิภาพและรองรับการเติบโตในอนาคตได้เป็นอย่างดี รวมถึงยังสามารถบริหารจัดการได้อย่างง่ายดายด้วยหน้า GUI ที่สวยงาม ทาง IBM จึงได้ทำการพัฒนาโซลูชัน IBM Cloud Private for Data หรือ ICP for Data ขึ้นมาเพื่อตอบโจทย์เหล่านี้โดยเฉพาะ ด้วยคุณสมบัติที่น่าสนใจดังนี้
- เป็นโซลูชัน Software ที่สามารถทำงานได้บน Hardware Server หลากหลาย คุ้มค่าต่อการลงทุน คิด License ตาม vCPU ที่ใช้งาน
- ติดตั้งมาให้พร้อมใช้งานได้ทันที ไม่ต้องวุ่นวายกับการ Integrate ระบบต่างๆ เข้าด้วยกันเอง
- รองรับการใช้งานได้ทั้ง Virtual Machine (VM) และ Container เพื่อให้องค์กรสามารถใช้งานทรัพยากรที่มีอยู่ได้อย่างคุ้มค่าและยืดหยุ่น ตอบรับต่อเทคโนโลยีใหม่ๆ ที่จะนำมาใช้งานได้
- มี Middleware, Database และเทคโนโลยีต่างๆ จาก IBM สำหรับใช้ในการจัดการกับข้อมูลในหลากหลายรูปแบบได้อย่างมีประสิทธิภาพ รองรับข้อมูลแบบ Structured Data ได้หลากหลายรูปแบบ และสามารถทำงานร่วมกับ Hortonworks เพื่อรองรับกรณีของการจัดการกับ Unstructured Data ภายในองค์กรได้
- มีเทคโนโลยี Data Integration เบื้องต้นให้พร้อมใช้งาน รองรับทั้งการ Clean, Prepare, Transform และ Catalog ได้ในตัว และในอนาคตจะมีเทคโนโลยีใหม่ๆ เสริมเพิ่มขึ้นเรื่อยๆ
- สามารถสร้าง Project และ Dashboard แยกสำหรับแต่ละโครงการได้ ทำให้บริหารจัดการข้อมูลแยกขาดจากกันในแต่ละโครงการได้
- สามารถติดตามการฝึกโมเดลทั้งหมดที่เกิดขึ้นได้ตลอดเวลา
- มีการ Integrate ระบบ Machine Learning เอาไว้ในตัว พร้อมทำการวิเคราะห์ Pattern ของข้อมูลได้ทันที
- สามารถทำงานร่วมกับ IBM Watson Studio, IBM Cognos on Cloud และ Framework ต่างๆ ของเทคโนโลยีในฝั่ง AI ได้ ทำให้องค์กรมีทางเลือกในการใช้งานเทคโนโลยีที่หลากหลาย ด้วยการนำโมเดลที่สร้างขึ้นมาไปใช้งานในระบบอื่นๆ ได้อย่างอิสระ
- มีระบบบริหารจัดการข้อมูลและการประมวลผลด้าน AI ทำให้องค์กรสามารถทำงานได้อย่างมีประสิทธิภาพ
- มีโซลูชันด้านระบบ Analytics หลากหลายให้เลือกใช้งานได้ทันทีในรูปแบบ Microservices
- สามารถบริหารจัดการได้ง่าย ทั้งในแง่ของการใช้งานและการจัดการด้าน Security ภายในระบบ
- สามารถทำงานได้ทั้งแบบ Hybrid Cloud และ Multi-Cloud เลือกได้ว่าจะนำข้อมูลและการประมวลผลส่วนใดอยู่ภายในองค์กรและภายนอกองค์กร
- บริหารจัดการระบบ Container ด้วย Kubernetes ได้อย่างยืดหยุ่น และเชื่อมต่อกับบริการอื่นๆ ได้ผ่าน API
- สามารถรวบรวมและจัดเตรียมข้อมูลได้อย่างรวดเร็ว
- มีการทำ Containerize สำหรับทั้ง Data และ Service เพื่อให้สามารถทำการ Deploy ระบบได้อย่างรวดเร็ว

โซลูชันนี้จะช่วยให้องค์กรสามารถวางระบบ Infrastructure ที่สามารถใช้จัดการข้อมูลได้อย่างมีประสิทธิภาพและพร้อมรองรับการเพิ่มขยายได้อย่างต่อเนื่องในอนาคต ทำให้องค์กรไม่ต้องพะวงกับประเด็นด้านการจัดการข้อมูลและการนำข้อมูลมาใช้อีกต่อไป และมุ่งไปสู่การนำข้อมูลต่างๆ เข้ามาวิเคราะห์เพื่อสร้างโอกาสใหม่ๆ ทางธุรกิจได้อย่างต่อเนื่อง

ปัจจุบันนี้ IBM Cloud Private for Data มีลิขสิทธิ์ในการใช้งานด้วยกัน 3 รูปแบบ ได้แก่
- Community Edition สำหรับการใช้งานเพื่อการทดสอบในระบบ Non-Production
- Cloud Native Edition สำหรับระบบขนาดเล็กเพื่อใช้ในการวิเคราะห์ข้อมูลเบื้องต้นในระบบ Production
- Enterprise Edition สำหรับระบบขนาดใหญ่พร้อมฟีเจอร์แบบสมบูรณ์ เพื่อใช้ในระบบ Production ขนาดใหญ่
ผู้ที่สนใจสามารถศึกษาข้อมูลเพิ่มเติมเกี่ยวกับโซลูชันได้ที่ https://www.ibm.com/analytics/cloud-private-for-data-journey-to-ai โดยสามารถทำการทดสอบระบบฟรีๆ หรือศึกษาข้อมูลเพิ่มเติมเกี่ยวกับตัวอย่างการใช้งานได้ที่ https://ibm-dte.mybluemix.net/ibm-cloud-private-for-data และสำหรับด้านล่างนี้เป็นตัวอย่างการใช้งาน IBM Cloud Private for Data ครับ
กรณีศึกษาการใช้งาน IBM Cloud Private for Data ในอุตสาหกรรมต่างๆ
IBM ได้เล่าถึงกรณีศึกษาของการใช้งาน IBM Cloud Private for Data ในอุตสาหกรรมต่างๆ หลากหลาย ได้แก่
- สถาบันการเงินในยุโรป ใช้สร้างบริการ Data & Analytics แบบ White Label ให้กับลูกค้ารายต่างๆ
- ธนาคารในแอฟริกา ใช้สร้างระบบ Hybrid Cloud และ Multi-Cloud สำหรับ Data Analytics และ Machine Learning
- ธนาคารในจีน ใช้สร้างระบบ eLoan Application ที่มีความสามารถในการทำ Compliance, Audit, Anti-Fraud และ Risk Management ในตัว
- ธุรกิจการบินและอวกาศในอเมริกาเหนือ ใช้ในการจัดการระบบ Data Analytics แบบครบวงจร ซึ่งเดิมทีใช้โซลูชัน Open Source เป็นหลักอยู่แล้ว
- สถาบันการเงินในอเมริกาเหนือ พัฒนาระบบ Enterprise Search Engine สำหรับค้นหาข้อมูลใน Data Source และ Analytics Asset
- ธนาคารในยุโรป ใช้สร้างระบบ Cognitive Platform เพื่อรองรีับการทำ Natural Language Processing และ Machine Learning ภายในองค์กร
จะเห็นได้ว่าโจทย์ส่วนใหญ่นั้นคือการนำ IBM Cloud Private for Data ไปใช้เป็นระบบโครงสร้างพื้นฐานให้กับระบบ Data Analytics ที่มีอยู่เดิม เพื่อต่อยอดทั้งในแง่ของการก้าวไปสู่ Hybrid Cloud, Multi-Cloud, AI ไปจนถึงการพัฒนา Application ทางด้าน Data เพื่อใช้งานภายในหรือให้บริการลูกค้าเป็นหลักนั่นเอง

ผู้ที่สนใจสามารถติดต่อทีมงาน IBM Thailand ได้ทันที
สำหรับผู้ที่สนใจในโซลูชันทางด้าน Big Data หรือ AI และต้องการพูดคุยกับทีมงาน IBM Thailand สามารถติดต่อทีมงานได้ทันทีที่ pakornki@th.ibm.com












