




![]()
นักวิจัยจาก Google ได้ใช้เทคโนโลยี Deep learning เพื่อแยกเสียงจากข้อมูล Audio ที่ถูกบันทึกในสภาพแวดล้อมที่มีมวลชนจำนวนมาก โดยระบบที่พัฒนาขึ้นเทียบเคียงได้กับความสามารถของสมอง หรือ ‘Cocktail party’ ที่แยกแยะและโฟกัสไปยังเสียงที่สนใจ 1 หรือมากกว่าในฝูงชนได้
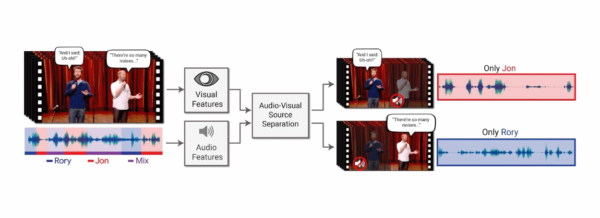
ระบบถูกออกแบบมาให้ทำงานกับข้อมูล Audio และวีดีโอพร้อมๆ กัน โดยอาศัยข้อมูลจากวีดีโอคุณภาพสูงของการพูดหรือการเรียนบน Youtube จำนวนกว่า 1 แสนวีดีโอ ทุกการพูดเกิดจากผู้พูดเพียงคนเดียวซึ่งทีมงานได้เทรนให้ AI จดจำเสียงตามการขยับริมฝีปากหรือปาก หลังจากนั้นนักวิจัยได้ขยายการทดลองโดยมีผู้พูดหลายคนและไม่มีพื้นฐานเกี่ยวกับเสียงนั้นมาก่อนเพื่อจำลองเหตุการณ์คล้ายกับความสามารถของสมอง ผลลัพธ์คือระบบสามารถแยกแยะเสียงที่มีผู้พูดหลายคนได้ อย่างไรก็ตามข้อจำกัดคือต้องปรากฏหน้าผู้พูดบนหน้าจอด้วยเพื่อให้ AI ทำงานเชื่อมโยงเสียงกับผู้พูดและจัดลำดับสิ่งที่ได้ยินได้
Google มีแผนที่จะนำเทคโนโลยีนี้ไปใช้กับผลิตภัณฑ์ของตน เช่น Assistant/Smart Speaker หรือการแสดงบทพูดแบบทันทีบน Google Glasses สำหรับผู้พิการหูหนวก หรือ การระบบแสดงบทพูดบน Youtube และ การแสดงบทพูดในซอฟต์แวร์จัดประชุมผ่านวีดีโอ นอกจากนี้ในสถานการณ์ของกล้องวงจรปิดที่บันทึกไว้ก็สามารถประยุกต์ใช้เพื่อช่วยเจ้าหน้าที่แยกแยะเสียงของบุคคลที่สนใจออกจากการรบกวนต่างๆ
ผู้สนใจสามารถติดตามเพิ่มเติมได้ที่ “Looking to Listen at the Cocktail Party: A Speaker-Independent Audio-Visual Model for Speech Separation.” หรือชมวีดีโอตามด้านล่าง



