Yahoo เปิดโอเพ่นซอร์ส library ที่เชื่อม TensorFlow เข้ากับ Apache Hadoop และ Spark เพื่อมให้นักพัฒนาสร้างโมเดล deep learning ที่ใช้ความสามารถของ Spark ในการเพิ่มขยายระบบและรันแบบ distributed ผ่าน CPU และ GPU ของ server cluster
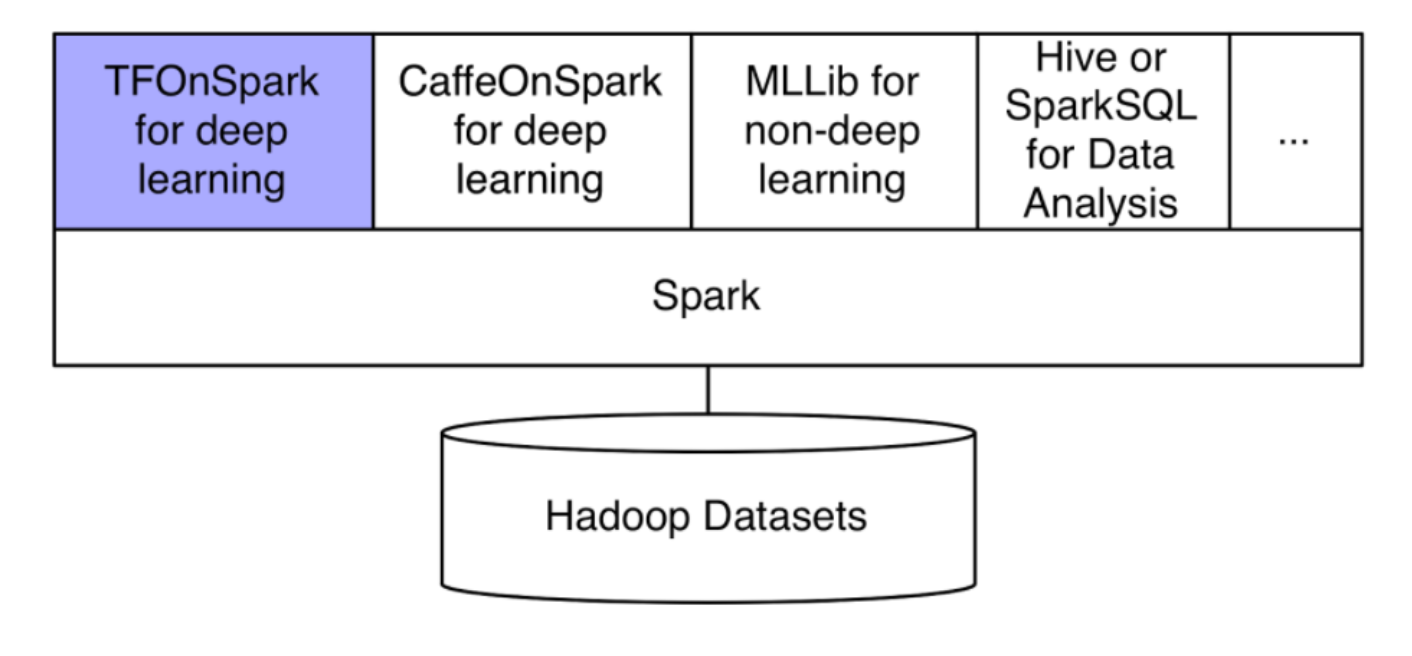
หลังจากได้ทดลองเครื่องมือที่มีอยู่แล้วอย่าง SparkNet และ TensorFrame เพื่อเชื่อมต่อ TensorFlow เข้ากับ Spark แต่ผลไม่เป็นที่น่าพอใจนัก นักพัฒนาของ Yahoo จึงเริ่มพัฒนาโปรเจค TensorFlowOnSpark ซึ่งทำให้สามารถรัน TensorFlow ร่วมกับ Spark ได้
จุดเด่นของ TensorFlowOnSpark มีดังนี้
- แปลงโค้ดจากโปรแกรม TensorFlow ที่มีอยู่แล้วได้ง่ายๆ
- รองรับฟังก์ชั่นของ TensorFlow ทั้งหมด: การเทรนแบบ synchronous/asynchronous, โมเดลและข้อมูลแบบ parallel, inferencing and TensorBoard
- การสื่อสารระหว่างเซิฟเวอร์โดยตรงทำให้โมเดลสามารถเรียนรู้ได้เร็วขึ้น
- สามารถนำชุดข้อมูลเข้ามายัง HDFS ผ่าน Spark หรือดึงออกผ่าน TensorFlow
- นำมาใช้งานร่วมกับ data processing pipeline และ library เช่น MLlib หรือ CaffeOnSpark ได้โดยง่าย
- มีการติดตั้งที่ง่ายทั้งบน cloud หรือ on-premise: CPU & GPU, ethernet และ Infiniband
Yahoo นับว่าเป็นผู้ใช้รายใหญ่รายหนึ่งของ Apache Spark เลยก็ว่าได้ โดยก่อนหน้านี้ Yahoo ได้เปิดโอเพ่นซอร์ส CaffeOnSpark ที่ช่วยให้นักพัฒนาสร้างโมเดล deep learning จาก Caffe ที่สามารถทำงานแบบ parallel ได้
ที่มา: