หากคุณกำลังมองหา solution ในการรวบรวมข้อมูลที่ทันสมัยและต้องการให้คุณภาพของข้อมูลในองค์กรมีความน่าเชื่อถือ เพิ่มความรวดเร็วในการเคลื่อนย้ายข้อมูล ทำให้องค์กรสามารถนำข้อมูลไปใช้ในการวิเคราะห์ได้มีประสิทธิภาพ IBM Data Integration คือคำตอบของคุณ

ปัจจุบันนี้ข้อมูลในองค์กรมีการเปลี่ยนแปลงอย่างรวดเร็ว มีการจัดเก็บข้อมูลที่แตกต่างกันและกระจายอยู่ในหลายระบบ ในขณะเดียวกันผู้บริหารทั้งฝั่ง IT และฝั่ง Business ก็พยายามที่จะมองหาการใช้ประโยชน์จากข้อมูลที่มีเพื่อนำมาขับเคลื่อนองค์กรให้สามารถแข่งขันกับคู่แข่งในตลาดได้ แต่ปัญหาที่เกิดขึ้นกับองค์กรส่วนใหญ่คือไม่สามารถใช้ข้อมูลที่มีอยู่นำมาใช้งานได้อย่างมีประสิทธิภาพ กระบวนการรวบรวมข้อมูลจึงเป็นสิ่งที่สำคัญเป็นลำดับต้นๆ ในการทำ Business Intelligence เนื่องจากข้อมูลที่ถูกนำมาวิเคราะห์จะต้องเป็นข้อมูลที่ถูกต้องและน่าเชื่อถือ ช่วยให้ผู้บริหารสามารถตัดสินใจได้รวดเร็วและดียิ่งขึ้น
สถาปัตยกรรมของระบบ BI โดยทั่วไปจะประกอบด้วยระบบคลังข้อมูล (Data Warehouse) หรือคลังข้อมูลขนาดย่อย (Data Mart) ซึ่งจะจัดเก็บข้อมูลจากฐานข้อมูลการดำเนินงานต่างๆ จากข้อมูลต้นทาง(Data Source) โดยอาจจะมีประเภทของข้อมูลที่แต่ต่างกันไปเช่น Excel, Text หรือ Database ที่ถูกจัดเก็บไว้คนละระบบฐานข้อมูล และมีเครื่องมือที่ช่วยให้ผู้ใช้งานเห็นข้อมูลและนำมาใช้ในการวิเคราะห์ข้อมูลในรูปแบบต่างๆ ในรูปแบบของ Report หรือ Dashboard ซึ่งกระบวนการทำงานเบื้องหลังของการจัดเก็บการรวบรวมข้อมูลไปจัดเก็บไว้ที่ Data Warehouse นั้นเรียกว่า Data Integration ซึ่งนิยามของ Data Integration นั้นยังรวมไปถึงการบิรหารจัดการข้อมูลที่มีการเคลื่อนไหวต่างๆ เช่น การรวบรวมข้อมูลเพื่อจัดเก็บไว้ที่ปลายทาง (Extract, Transform and Load), การตรวจสอบคุณภาพของข้อมูลเพื่อให้ได้ข้อมูลที่ถูกต้อง (Data Quality) และการจำลองข้อมูลเพื่อรองรับการใช้งานที่ต่าง Environment กัน (Data replication) เป็นต้น

IBM Data Integration มี Solution ในการรวบรวมข้อมูลที่ทันสมัยพร้อมทั้งสามารถตรวจสอบคุณภาพของข้อมูลเพื่อให้ได้ข้อมูลที่ถูกต้องน่าเชื่อถือ รองรับได้ทั้งข้อมูลที่มีจำนวนมากและข้อมูลที่มีความซับซ้อน สามารถทำงานร่วมกับ Environment ต่างๆ ได้ทั้ง On-Premise, Multi-Cloud และ Hybrid-Cloud เพิ่มความรวดเร็วในการเคลื่อนย้ายข้อมูล ทำให้องค์กรสามารถนำข้อมูลไปใช้ในการวิเคราะห์ได้อย่างมีประสิทธิภาพและรวดเร็วมากยิ่งขึ้น
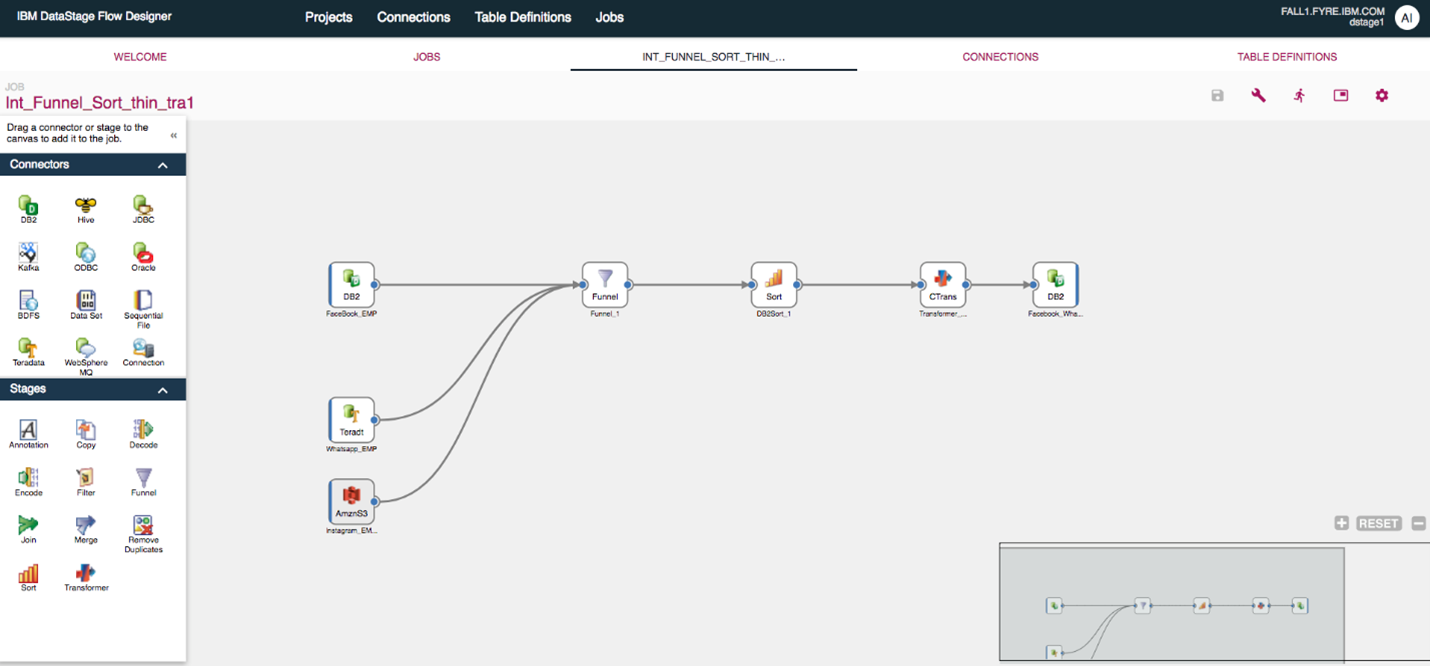
IBM Infosphere Datastage
IBM Infosphere Datastage เป็นหนึ่งในเครื่องมือการทำ Data Integration โดยสามารถออกแบบ, พัฒนาและควบคุมงานต่างๆ ที่มีการเคลื่อนย้ายและมีการเปลี่ยนแปลงข้อมูล โดย IBM Infosphere Datastage นั้นจะมีลักษณะการใช้งานแบบ GUI (Graphic User Interface) สำหรับการพัฒนางานที่ต้องการรวบรวมข้อมูลจากระบบต้นทางไปยังระบบปลายทาง มีความสามารถเปลี่ยนแปลงข้อมูลเพื่อให้อยู่ในรูปแบบเดียวกันเพื่อที่จะส่งไปยัง Data Warehouse, Data marts, Database อื่นๆ รวมไปถึงระบบ Application ปลายทางได้อีกด้วย IBM Infosphere Datastage สามารถรองรับการทำงานทั้งรูปแบบ Extract, Transform, Load (ETL) และ Extract, Load, Transform (ELT) เพื่อความเหมาะสมกับสภาพแวดล้อมของในแต่ละองค์กร นอกจากนั้นยังสามารถประมวลผลงานแต่ละงานพร้อมๆ กัน (Parallel Processing) เพื่อรองรับข้อมูลที่เพิ่มขึ้นจำนวนมากในอนาคตได้อีกด้วย
Key Feature & Benefit:
- Ease of use ใช้งานง่าย โดยสามารถออกแบบงานต่างๆ เพียงครั้งเดียวและปรับใช้งานได้ทุกครั้งที่ต้องการ รองรับงานประเภท Batch และ Real-Time ใช้งานได้ทั้งในรูปแบบ Extract, Transform, Load (ETL) หรือ Extract, Load, Transform (ELT) มีเครื่องมือที่เป็น Graphic User Interface เพื่อใช้สำหรับบริหารจัดการและสร้าง Jobs ต่างๆเพื่อใช้ในการรวบรวมข้อมูล รองรับการทำงานทั้งในรูปแบบการติดตั้งบนเครื่อง Client และบน web-based เพื่อให้สามารถทำงานได้อย่างรวดเร็ว
- Support simple-to-highly complex transformation logic to the data มี Library ที่ครอบคลุมใช้สำหรับงานที่ต้องมีการเปลี่ยนแปลงข้อมูล (Transform) ช่วยให้ง่ายต่อการรวบรวมข้อมูลหลากหลายประเภท
- Reusable job templates สามารถนำ Jobs งานที่ถูกสร้างไว้นำกลับมาใช้ได้ใหม่เพื่อเป็นมาตรฐานในการ Transform ข้อมูลในกรณีที่มีคนใช้งานจำนวนมาก
- Extensive set of prebuilt connectors and stages รองรับการเชื่อมเพื่อเคลื่อนย้ายข้อมูลได้อย่างครอบคลุม แม้ว่าสภาพแวดล้อมในจัดเก็บข้อมูลจะแตกต่างกันเช่น การเคลื่อนย้ายข้อมูลระหว่าง Multi cloud sources และ ระบบ Data warehouses ที่อยู่บน On premise เป็นต้น
- Automated failure detection มีเครื่องมือเพื่อตรวจสอบความผิดพลาดโดยสามารถแจ้งเตือนได้ทันทีเมื่อเกิดปัญหา (UI Debugger)
- Parallel engine and automated load balancing รองรับการทำงานแบบคู่ขนาน (Parallelism) ช่วยให้งานที่มีปริมาณข้อมูลจำนวนมากสามารถทำเสร็จได้ตรงตามเวลาที่กำหนดไว้
- In-flight data quality and Governance ข้อมูลงานต่างๆ ที่ถูกจัดเก็บไว้สามารถนำไปใช้ร่วมกับการทำ Data Quality และ Data Profiling ที่เป็น Modules ของ IBM InfoSphere Information Server ได้ด้วย
IBM Infosphere QualityStage
IBM InfoSphere QualityStage ได้รับการออกแบบมาเพื่อสนับสนุนการควบคุมคุณภาพของข้อมูลในองค์กรให้มีความถูกต้องน่าเชื่อถือ ช่วยให้องค์กรสามารถตรวจสอบรายการข้อมูลที่ไม่ถูกต้องออกไปและจัดการข้อมูลที่มีความเกี่ยวข้องกันให้เป็นมาตรฐานเดียวกัน ทำให้เกิดข้อมูลที่มีคุณภาพก่อนที่จะส่งต่อไปยังกระบวนจัดเก็บข้อมูลไว้ที่ปลายทางเช่น Data Warehouse, Application ต่างๆ และระบบการจัดการข้อมูลหลัก (Master Data Management) เป็นต้น

Key Feature & Benefit:
- Deep data profiling ใช้การทำ Data Profiling และการวิเคราะห์ข้อมูลเชิงลึกเพื่อให้เข้าใจถึงเนื้อหา, คุณภาพ และโครงสร้างของข้อมูล นอกจากนั้นยังสามารถวิเคราะห์ Column ที่จัดเก็บข้อมูล, การจำแนกข้อมูลประเภทต่างๆ, การให้คะแนนเพื่อชี้วัดคุณภาพของข้อมูล, การวิเคราะห์เชื่อมโยงความสัมพันธ์ และสามารถวิเคราะห์ข้อมูลที่มีความซ้ำซ้อนกันได้อีกด้วย
- More than 200 built-in data quality rules ควบคุมการนำเข้าข้อมูลที่ไม่ต้องการ โดยสามารถกำหนดเงื่อนไขของคุณภาพข้อมูลในขณะที่มีการ Transform ข้อมูลการที่จะ Load ข้อมูลไปเก็บไว้ที่ระบบปลายทางเช่น Data Warehouse, Data Lake หรือลงใน Application ต่างๆ ซึ่งภายในซอร์ฟแวร์จะมีตัวอย่างเงื่อนไขให้อยู่แล้วมากกว่า 200 เงื่อนไขให้องค์กรต่างๆ เลือกใช้งาน เพื่อให้มั่นใจว่าข้อมูลที่จะนำไปใช้เป็นข้อมูลที่น่าเชื่อถือ
- More than 250 built-in data classes สามารถระบุตำแหน่งข้อมูลส่วนบุคคล (Personally Identifiable Information), ข้อมูลที่ละเอียดอ่อน (Sensitive Data) และข้อมูลอื่นๆ ที่เก็บไว้ในฐานข้อมูล องค์กรสามารถระบุชนิดของข้อมูลที่จัดเก็บไว้ใน Column ต่างๆ ได้มากกว่า 250 ชนิด รวมถึงข้อมูลประเภท Credit Card, รหัสผู้เสียภาษี และเบอร์โทรศัพท์ โดยสามารถสร้างและกำหนดประเภทของ Data Classes ได้ 3 ชนิดคือ Valid values list, Regular Expression (rex) และ Java class
- Data standardization and record matching สามารถทำ Data Standardization โดยการสังเคราะห์ข้อมูลทั้งหมดที่มาจากแหล่งข้อมูลต่างๆ เป็นรูปแบบหรือมารตฐานเดียวกันสำหรับการนำส่งต่อไปยังปลายทางที่กำหนดไว้ ลบข้อมูลที่ซ้ำกันและรวมระบบต่างๆ ให้มองเห็นเป็นมุมมองเดียวกันเพื่อสร้างข้อมูลที่ถูกต้องสามารถเชื่อถือได้
IBM InfoSphere Data Replication
IBM InfoSphere Data Replication เป็นการนำข้อมูลของ Logs ที่มีการเปลี่ยนแปลงจาก Transection ที่เกิดขึ้นมาใช้งานให้เกิดประโยชน์เพื่อรองรับการรวมข้อมูลต่างๆ และการนำข้อมูลไปวิเคราะห์ได้ทันที ช่วยให้องค์กรมีความยืดหยุ่นในการทำซ้ำข้อมูล (Replication Data) ระหว่างแหล่งข้อมูลที่แตกต่างกันหรืออาจจะอยู่คนละสถานที่กัน ทำให้การโยกย้ายหรือการ Upgrade ฐานข้อมูลสามารถทำได้โดยไม่จำเป็นจะต้องหยุดระบบ (Zero-Downtime) นอกจากนั้น IBM InfoSphere Data Replication ยังสามารถรองรับการทำงานอย่างต่อเนื่องเมื่อ Database หลักมีปัญหาเกิดขึ้นก็สามารถสลับไปใช้งาน Database สำรองที่อยู่คนละสถานที่กันได้ภายในไม่กี่นาที หรือในบางที่อาจจะใช้เวลาแค่หลักวินาทีเลยทีเดียว

Key Feature & Benefit:
- Continuous availability ช่วยให้ Database สามารถทำงานได้อย่างต่อเนื่องจาก Solution High Availability ทั้งภายใน Datacenter และ DR Site
- Multi-source, target and replication topology support สามารถนำไปใช้กับกระบวนการต่างๆ ได้เช่น High Availability, Database migration, Application consolidation, Dynamic warehousing, Master Data Management (MDM) Service-oriented architecture (SOA), Business Analytics, Extract-Transform-Load (ETL) และการทำ Data Quality เป็นต้น โดย InfoSphere Data Replication มีความสามารถในการโหลดข้อมูลแบบ Real-Time ไปยังระบบฐานข้อมูลปลายทาง ซึ่งสามารถช่วยให้องค์กรเพิ่มความคล่องตัวในการดำเนินธุรกิจได้ดียิ่งขึ้น
- Log-based change data capture capabilities ไม่มีการ Queries ข้อมูลซ้ำอีกครั้งเพื่อนำข้อมูลไปเก็บไว้ที่ปลายทางซึ่งเป็นสาเหตุหนึ่งที่ทำให้ระบบ Application หรือ Database จะต้องทำงานหนักมากยิ่งขึ้น โดยระบบการทำงานของ InfoSphere Data Replication นั้นจะทำการอ่านข้อมูลจาก logs ของ Database และ Capture ข้อมูลการเปลี่ยนแปลงที่เกิดขึ้นส่งให้ระบบที่อยู่ ช่วยให้มั่นใจได้ว่าประสิทธิภาพของ Application และ Database ต้นทางจะไม่ได้รับผลกระทบ
ผู้ที่สนใจสามารถกรอกแบบฟอร์มเพื่อเข้าร่วม Webinar ในหัวข้อ “Transform data from different source into a trusted with IBM Data Integration” ในวันพุธที่ 18 สิงหาคม 2564 เวลา 14.00 – 15.30 น. ได้ทันทีที่ : https://us06web.zoom.us/webinar/register/WN_p5_QvwnaRQqqTrhl43g6tA
สอบถามข้อมูลเพิ่มเติมได้ที่ บริษัท คอมพิวเตอร์ยูเนี่ยน จำกัด
โทร 02 311 6881 #7156,7158 หรือ email : cu_mkt@cu.co.th
เขียนบทความโดย คุณอนุวรรตน์ ชำนาญเวช
Presales Software Specialist
บริษัท คอมพิวเตอร์ยูเนี่ยน จำกัด