เมื่อวันที่ 6 พฤศจิกายน 2025 ที่ผ่านมา ทาง Datadog ร่วมกับ DevSecOps Community Thailand (DCT), Opsta (Thailand) และ TechTalkThai จัดงาน DevSecOps Meetup: Reliability Unleashed: SRE at Scale ณ TechTalkThai Meetup Space

ภายในงานมีผู้เข้าร่วมจากหลากหลายองค์กรด้าน IT มาแลกเปลี่ยนมุมมองเกี่ยวกับแนวทางของ Site Reliability Engineering (SRE) — แนวคิดที่เน้นการออกแบบระบบให้เสถียร ลดความซับซ้อน และเพิ่มประสิทธิภาพการทำงานร่วมกันระหว่างทีม พร้อมผู้เชี่ยวชาญจาก Datadog ที่มาเล่าถึงตัวช่วยน่าสนใจที่ผสานพลัง AI เข้ากับ Observability เพื่อให้ทีมสามารถมองเห็นภาพรวมของระบบได้แบบครบวงจร รู้ปัญหาก่อนเกิดเหตุ และตอบสนองได้อย่างรวดเร็วยิ่งขึ้น

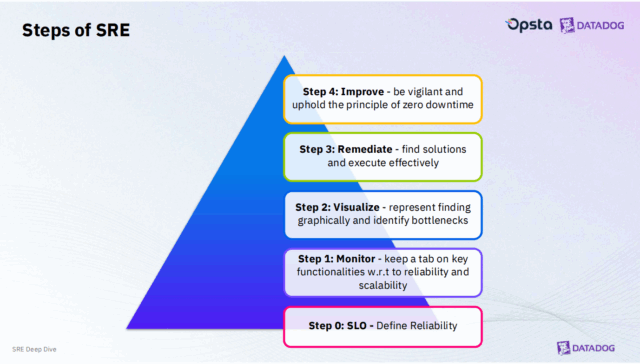
SRE Deep Dive โดย คุณเดียร์ – จิรายุส นิ่มแสง, CEO & Founder, Opsta
ในเซสชันนี้ คุณเดียร์ได้พาผู้เข้าร่วมสำรวจบทบาทแท้จริงของ SRE — จากหลักการสำคัญอย่าง SLI, SLO, SLA, Error Budget ไปจนถึงการทำงานในชีวิตจริงของ SRE ทั้งการรับมือกับเหตุการณ์ On-call Incidents — เหตุการณ์ระบบผิดปกติที่ต้องเข้าไปแก้ไขแบบเรียลไทม์ และการทำ Post Mortem หลังการแก้ปัญหา เพื่อวิเคราะห์สาเหตุและหาทางป้องกันไม่ให้เกิดซ้ำในอนาคต
คุณเดียร์ได้อธิบายให้เห็นว่า SRE ไม่ใช่เป็นหลักแนวคิดแบบ DevOps แต่ SRE คือตำแหน่งงาน ที่มีหลักปฏิบัติเป็นขั้นตอนอย่างชัดเจน ในการโฟกัสไปที่เพิ่มความน่าเชื่อถือ (Reliability) ของระบบ
ทั้งยังอธิบายถึงความแตกต่างของ Monitoring, Observability และ SRE — ที่แม้ทั้งหมดจะเกี่ยวข้องกับการดูแลระบบ แต่มีจุดเน้นต่างกัน โดย Monitoring คือการ “เก็บข้อมูลให้มากที่สุด เพื่อเอามาดูเมื่อเกิดปัญหา”, Observability คือ “การโฟกัสที่การทำระบบ Monitor ที่อธิบายระบบ และสามารถค้นหาส่วนที่เป็นปัญหาได้อย่างรวดเร็ว” ส่วน SRE คือ “ตำแหน่งและหลักการปฏิบัติที่เป็นขั้นเป็นตอนในการทำ Observability และ Reliability ของระบบ”
หัวใจของ SRE คือการกำหนด Service Level Indicator (SLI), Service Level Objective (SLO) และ Service Level Agreement (SLA) โดยมี Error Budget เพื่อสร้างสมดุลระหว่าง “ความเสถียรของระบบ” และ “ความเร็วในการปล่อยฟีเจอร์ใหม่” โดยมีแนวคิดสำคัญว่า
“100% reliability is the wrong target for everything.”
เพราะยิ่งทีมโฟกัสที่ “ความเสถียร 100%” มากเท่าไหร่ ก็จะยิ่งมีเวลาน้อยลงในการพัฒนา feature ใหม่ ๆ หรือปรับปรุงประสบการณ์ผู้ใช้ จึงเกิดเป็นแนวคิด Error Budget “คือความผิดพลาดที่ยอมรับได้” เพื่อสร้างสมดุลระหว่าง ความน่าเชื่อถือของระบบ และ ความสามารถในการพัฒนานวัตกรรมอย่างต่อเนื่อง
คุณเดียร์ได้ยกตัวอย่าง “ระบบเกมออนไลน์” เพื่ออธิบายวิธีคิดของ SRE ในการออกแบบตัวชี้วัดความน่าเชื่อถือของระบบ (SLI/SLO) โดยเริ่มจากการนิยามว่า “อะไรคือการทำงานที่ถูกต้อง” และ “เร็วเพียงใดที่ผู้ใช้จะพึงพอใจ” เช่น การวัดอัตราความสำเร็จ (availability) ของการโหลดหน้าโปรไฟล์ผู้เล่น และ ความเร็วในการตอบสนองของระบบ (latency) เพื่อให้เห็นว่า ความสำเร็จของระบบไม่ได้ขึ้นอยู่กับตัวเลขทางเทคนิคเท่านั้น แต่ขึ้นอยู่กับประสบการณ์จริงของผู้ใช้ ซึ่งเป็นตัวชี้วัดความน่าเชื่อถือของระบบอย่างแท้จริง

SRE in Action: From Principles to Real-World Reliability
โดย คุณนัทที จิรัฐติวงศ์วิบูล และ คุณวารัชญ์ วงศ์ไพโรจน์
Senior Sales Engineer , Datadog
ในเซสชันจากทีม Datadog ได้มีการต่อยอดแนวคิดจากทฤษฎีไปสู่การปฏิบัติจริง โดยอธิบายว่า SRE คือกระบวนการเปลี่ยน “ความเสถียรของระบบ” ให้กลายเป็นศาสตร์ของวิศวกรรม (Engineering Discipline) ที่สามารถวัดผล ปรับปรุง และพัฒนาได้อย่างเป็นระบบ พร้อมทั้งชี้ให้เห็นว่าเครื่องมือของ Datadog สามารถช่วยสนับสนุนทุกขั้นตอน ตั้งแต่การกำหนดตัวชี้วัดด้านความเสถียรของระบบ ไปจนถึงการปรับปรุงระบบให้มีความเสถียรตามระดับที่ต้องการ
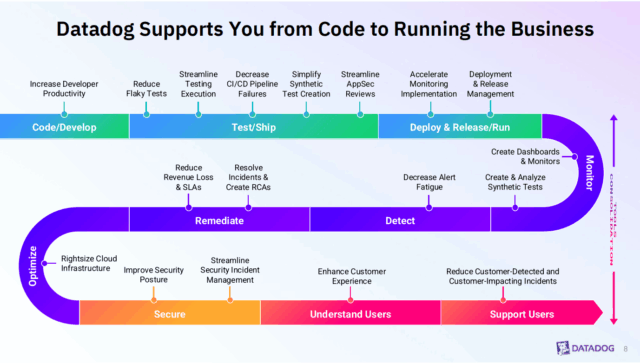
นอกจากนี้ ยังได้มีการสาธิตวิธีการใช้ Datadog เพื่อ Operationalize SRE ครอบคลุมตั้งแต่ต้นน้ำ (development) ไปจนถึงปลายน้ำ (user experience) โดย Datadog เข้ามาช่วยเพิ่มประสิทธิภาพให้กับทีมในหลายด้าน ไม่ว่าจะเป็นการเพิ่มประสิทธิภาพการทำงานของนักพัฒนา (Increase Developer Productivity), ลดปัญหา Flaky Tests, ทำให้การสร้าง Synthetic Tests เป็นเรื่องง่ายขึ้น, เพิ่มมุมมองในขั้นตอน CI/CD Pipeline, ตลอดจนเสริมความสามารถด้าน Observability และความปลอดภัยทั้งในส่วนโครงสร้างพื้นฐาน บริการบนคลาวด์ และแอปพลิเคชัน
ทั้งหมดนี้ช่วยให้ทีม SRE และ DevSecOps มีเครื่องมือที่พร้อมรองรับกระบวนการทำงานแบบวัดผลได้ตลอดเวลา และสร้างความมั่นใจให้ระบบมีความเสถียรอย่างต่อเนื่อง
ในเซสชันยังมีการสาธิตการทำงานของระบบ AI Incident Response ที่เมื่อเกิดเหตุระบบล่ม AI จะตรวจจับและแจ้งเตือนอัตโนมัติ พร้อมโทรแจ้งทีมดูแลแบบ real-time ทันที — สะท้อนให้เห็นถึงอนาคตของ SRE ที่ขับเคลื่อนด้วยความอัจฉริยะและอัตโนมัติได้อย่างลงตัว

งาน DevSecOps Meetup: Reliability Unleashed: SRE at Scale ในครั้งนี้ได้รับเสียงตอบรับอย่างอบอุ่นจากผู้เข้าร่วมในสาย IT จากหลายอุตสาหกรรม ขอขอบคุณ Datadog ที่ร่วมเป็นพาร์ทเนอร์หลักในการจัดงาน รวมถึง Opsta, TechTalkThai และ DevSecOps Community Thailand ที่ร่วมกันสร้างพื้นที่แลกเปลี่ยนความรู้สำหรับวงการ DevSecOps ในประเทศไทย
ติดตามกิจกรรม Meetup ครั้งต่อไปได้ที่
📍 Facebook Page: DevSecOps Community Thailand