




ในยุคดิจิทัลปัจจุบัน เรากำลังใช้ชีวิตอยู่ในโลกที่ข้อมูลถูกขับเคลื่อนด้วยความเร็วระดับวินาที ทุกคำถามที่เกิดขึ้นในชีวิตประจำวันสามารถหาคำตอบได้ทันทีผ่าน Search Engine ระดับโลก หรือเทคโนโลยี Generative AI ที่มีความฉลาดล้ำเลิศ แต่ในทางกลับกัน เมื่อพิจารณาถึงสภาพแวดล้อมการทำงานภายในองค์กรส่วนใหญ่ เรากลับพบความย้อนแย้งที่น่าสนใจประการหนึ่ง นั่นคือ “ข้อมูลที่อยู่ใกล้ตัวที่สุด กลับเป็นข้อมูลที่เข้าถึงได้ยาก”

ข้อมูลสำคัญไม่ว่าจะเป็นสัญญาจ้างคู่ค้าที่เซ็นไว้เมื่อหลายปีก่อน นโยบายภายในที่เพิ่งมีการแก้ไขล่าสุด หรือรายงานผลการดำเนินงานรายสาขาในไตรมาสที่ผ่านมา ข้อมูลเหล่านี้เปรียบเสมือนเส้นเลือดใหญ่ที่หล่อเลี้ยงการตัดสินใจในทุกวัน แต่ในทางปฏิบัติ ข้อมูลเหล่านี้กลับถูกกักเก็บอยู่ในรูปแบบที่กระจัดกระจาย หรือที่เรียกว่า Information Silos ไม่ว่าจะเป็นในระบบ Email, Cloud Drive, ระบบ ERP หรือฐานข้อมูลที่ซับซ้อน ซึ่งต้องอาศัยผู้เชี่ยวชาญเฉพาะทางในการดึงข้อมูลออกมา สิ่งที่เกิดขึ้นคือ พนักงานที่มีทักษะสูงต้องเสียเวลาส่วนใหญ่ของวันไปกับการ “ค้นหา” (Searching) แทนที่จะเป็นการ “สร้างคุณค่า” (Value Creation) จากข้อมูลเหล่านั้น
-
ต้นทุนที่ซ่อนอยู่ภายใต้ “ชั่วโมงการค้นหา” (The Hidden Cost of Inefficiency)
ปัญหาการหาข้อมูลไม่เจอมักถูกมองว่าเป็น “ความรำคาญใจ” ในการทำงาน แต่ในเชิงธุรกิจ นี่คือความสูญเสียทางเศรษฐกิจที่มหาศาล จากการศึกษาของสถาบันวิเคราะห์ข้อมูลระดับโลกอย่าง McKinsey Global Institute พบสถิติว่า พนักงานที่ใช้ทักษะความรู้ (Knowledge Workers) ต้องสูญเสียเวลาโดยเฉลี่ยสูงถึง 1.8 ชั่วโมงต่อวัน หรือคิดเป็นเกือบ 20% ของเวลาทำงานทั้งหมด เพียงเพื่อค้นหาและรวบรวมข้อมูลภายในองค์กร อ้างอิงจาก: McKinsey Global Institute Report -
เมื่อปริมาณข้อมูลเพิ่มขึ้น แต่ความสามารถในการเข้าถึงลดลง
ในทศวรรษที่ผ่านมา องค์กรส่วนใหญ่เผชิญกับภาวะข้อมูลท่วมท้น ข้อมูลถูกสร้างขึ้นทุกชั่วโมงในหลากหลายรูปแบบ ทั้งข้อมูลที่มีโครงสร้างชัดเจน (Structured Data) ในฐานข้อมูล และข้อมูลที่ไม่มีโครงสร้าง (Unstructured Data) เช่น ไฟล์เอกสาร PDF, บันทึกการประชุม หรืออีเมลโต้ตอบ ปัญหาหลักไม่ได้อยู่ที่ปริมาณข้อมูล แต่อยู่ที่สถาปัตยกรรมในการสืบค้น (Search Architecture) ระบบสืบค้นข้อมูลในองค์กรส่วนใหญ่มักทำงานที่ชั้น Application Layer ซึ่งทำหน้าที่เพียงแค่การจับคู่คำสำคัญ (Keyword Matching) เท่านั้น หากพนักงานจำชื่อไฟล์ไม่ได้ หรือใช้คำค้นหาที่ไม่ตรงกับที่ระบุไว้ในเอกสาร ระบบก็จะไม่สามารถดึงข้อมูลที่ต้องการออกมาได้ กระบวนการนี้จึงเปลี่ยนจากการ “ค้นหา” กลายเป็นการ “สืบค้น” ที่ต้องอาศัยเวลาอย่างอย่างมาก
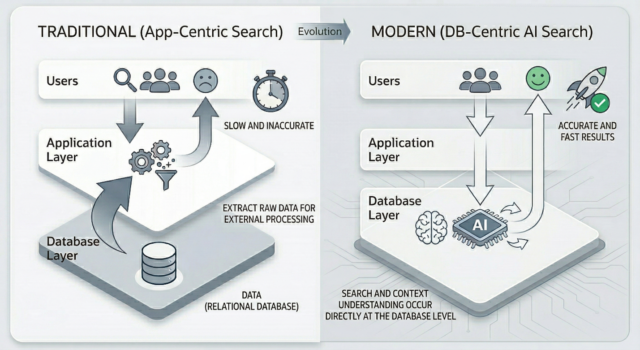
Diagram: วิวัฒนาการของการสืบค้นจาก Application Layer สู่ Database Layer
- แบบเดิม (App-Centric Search): ระบบต้องดึงข้อมูลดิบออกมาประมวลผลภายนอก ทำให้ช้าและคลาดเคลื่อน
- แบบใหม่ (DB-Centric AI Search): การค้นหาและทำความเข้าใจบริบทเกิดขึ้นที่ระดับฐานข้อมูลโดยตรง ทำให้ได้ผลลัพธ์ที่แม่นยำและรวดเร็ว
-
จุดเปลี่ยนสำคัญ: จากการ “สืบค้น” สู่การ “สร้างความเข้าใจ” ในฐานข้อมูล (Database Understanding)
หัวใจสำคัญของการแก้ปัญหานี้ไม่ใช่การเพิ่มระบบค้นหาซ้อนทับลงไป แต่คือการย้ายความสามารถในการ “คิด” และ “ทำความเข้าใจบริบท” ลงไปไว้ที่ระดับโครงสร้างพื้นฐานของข้อมูลโดยตรง Oracle Database 26ai ก้าวข้ามขีดจำกัดของฐานข้อมูลแบบเดิม ด้วยการทำให้ฐานข้อมูลมีเลเยอร์ของความเข้าใจ (Semantic Layer) ที่สามารถตีความข้อมูลมหาศาลขององค์กรได้ประหนึ่งว่า AI เป็นผู้ดูแลระบบที่รู้จักข้อมูลทุกตาราง
- AI Vector Search (การเข้าใจความหมายเชิงลึก): แทนที่จะเก็บข้อมูลเป็นเพียงตัวอักษร แต่จะแปลงข้อมูลทุก
ประเภท ไม่ว่าจะเป็นข้อความในเอกสารสัญญาหรือบันทึกการประชุม ให้กลายเป็นค่าความหมายในเชิงคณิตศาสตร์ (Vectors) ทำให้ AI สามารถ “เข้าใจ” ได้ว่าพนักงานกำลังถามถึงอะไร แม้พนักงานจะใช้คำเรียกที่ต่างออกไป ระบบจะมองหาข้อมูลที่มีความหมายใกล้เคียงที่สุดมาตอบได้อย่างแม่นยำ - Select AI (การเชื่อมโยงภาษาคนกับโครงสร้างฐานข้อมูล): นี่คือจุดเปลี่ยนที่แท้จริง เพราะ AI จะทำหน้าที่เป็น “สะพาน” ที่เข้าใจทั้งภาษาพูดของพนักงาน และเข้าใจโครงสร้างตารางข้อมูล (Schema) ที่ซับซ้อนขององค์กร เมื่อมีการถามคำถามเชิงสถิติหรือตัวเลข ระบบจะไม่ได้แค่ไปหาไฟล์มาให้ แต่จะทำการ “เขียนคำสั่งดึงข้อมูลสด” (Dynamic SQL Generation) จากฐานข้อมูลโดยตรง เพื่อสรุปเป็นคำตอบที่ถูกต้องที่สุดในขณะนั้น
-
Enterprise AI Advisor: แอปพลิเคชันผู้ช่วยอัจฉริยะที่เปลี่ยนข้อมูลเป็นคำตอบ ถูกออกแบบมาเป็นแพลตฟอร์มกลางที่เชื่อมต่อทุกจุดเข้าด้วยกัน
- Seamless User Experience: พนักงานเข้าถึงข้อมูลผ่าน Interface รูปแบบการสนทนา (Chat) ที่เรียบง่าย สามารถถามคำถามที่ซับซ้อนและได้รับสรุปข้อมูลที่พร้อมใช้งานทันที
- Data Sovereignty & Security: ในฐานะองค์กร ความปลอดภัยของข้อมูลคือสิ่งสำคัญที่สุด AI Advisor โดยข้อมูลทั้งหมดจะถูกประมวลผลอยู่ภายใน Infrastructure ขององค์กร (On-premises หรือ Private Cloud) โดยไม่มีการส่งข้อมูลออกไปยัง AI สาธารณะ ข้อมูลและความลับทางการค้าจึงได้รับการปกป้องอย่างสมบูรณ์
- Scalability & Governance: มาพร้อม Admin Panel ที่ช่วยให้ฝ่าย IT สามารถบริหารจัดการสิทธิ์การเข้าถึงข้อมูล (Role-Based Access Control) ได้อย่างรัดกุม มั่นใจได้ว่าพนักงานจะเข้าถึงข้อมูลได้เฉพาะส่วนที่ได้รับอนุญาตเท่านั้น
บทสรุป “ก้าวสู่การเป็น Data-Driven Organization อย่างแท้จริง”
การเปลี่ยนผ่านสู่ดิจิทัล (Digital Transformation) ไม่ใช่เพียงการมีข้อมูลในระบบให้ได้มากที่สุด แต่คือการทำให้ข้อมูลเหล่านั้น “ทำงานเพื่อเรา” การนำเทคโนโลยี AI มาปรับใช้ที่ระดับรากฐานของข้อมูล จะช่วยเปลี่ยนจากสภาวะที่ข้อมูลเป็น “ภาระในการค้นหา” ให้กลายเป็น “อาวุธในการตัดสินใจ”
เมื่อพนักงานไม่ต้องสูญเสียเวลาวันละเกือบ 2 ชั่วโมงไปกับการตามหาไฟล์ พวกเขาจะมีเวลาและพลังงานไปกับการคิดกลยุทธ์ การดูแลลูกค้า และการสร้างสรรค์นวัตกรรมใหม่ๆ ซึ่งนี่คือจุดเริ่มต้นของการสร้างความได้เปรียบทางธุรกิจอย่างยั่งยืนในยุค AI
สนใจข้อมูลเพิ่มเติม ติดต่อได้ที่ 🎯
📧 Email : contact@firstlogic.co.th
🌍 Website : www.firstlogic.co.th
📌Facebook Page : https://www.facebook.com/FirstLogicTH/
🚩Linkedin Page : www.linkedin.com/in/first-logic-company-limited-875360262










